
Plutôt femme Partagé Plutôt homme
18-29 ans 361 150 72
30-44 ans 1425 363 200
45-59 ans 1458 284 142
60 ans et plus 1226 137 105Initiation à l’analyse statistique
ED de l’Université de Bordeaux
2026
Séance 2 : Explorer et investiguer des variables qualitatives
Claire Kersuzan
PUD-Bx / Progedo · LifeObs / Ined · COMPTRASEC / UB
Karine Onfroy
Bordeaux School Economics (BxSE) / UB
DE LA DESCRIPTION À LA RELATION
Objectifs de la séance
Dans cette séance, on va apprendre à :
décrire une relation entre 2 variables qualitatives
construire et interpréter un tableau croisé ;
raisonner en proportions, en %
quantifier l’incertitude autour d’un résultat ;
comprendre la logique des tests d’hypothèse ;
interpréter une association avec rigueur et nuance.
Question fil rouge
Tout au long de cette séance, nous allons essayer de répondre à une question :
Quand deux variables semblent liées (ex : On observe que les jeunes utilisent davantage le vélo que les personnes âgées), comment savoir si cette relation entre l’âge et l’utilisation du vélo est :
- réelle ?
- importante ?
- robuste ?
- interprétable ? que peut-on réellement en conclure ?
Rappel de la séance 1
Lors de la séance précédente, nous avons appris à :
- comprendre d’où viennent les données ;
- identifier les variables ;
- distinguer différents types de variables ;
- décrire une variable ;
- repérer des problèmes dans les données.
Nous avons travaillé variable par variable.
Jusqu’ici, nous avons décrit les variables une par une. Dans cette séance, nous allons changer de perspective :
nous allons chercher à comprendre comment plusieurs variables sont liées entre elles.
Questions typiques
Selon les disciplines, cela peut prendre des formes très différentes :
le type d’erreur observée varie-il selon l’algorithme utilisé ?
certaines espèces sont-elles plus présentes selon le type d’habitat ?
les usages numériques diffèrent-ils selon les plateformes ?
la répartition des tâches domestiques varie-t-elle selon l’âge ou le diplôme ?
le mode de déplacement diffère t’il selon la catégorie d’âge ?
Derrière ces exemples très différents, on retrouve souvent la même question statistique :
la distribution observée d’une variable varie t’elle selon les groupes à comparer ?
Point commun entre ces exemples
L’objectif est de comprendre :
si les modalités de la variable observée se répartissent différemment selon les groupes … … ou au contraire de manière similaire.
Ce qu’il faudra apprendre à distinguer
Au cours de cette séance, il sera important de distinguer plusieurs niveaux de raisonnement :
ce que l’on observe dans les données
ce que l’on estime à partir de l’échantillon
ce que l’on teste statistiquement
ce que l’on peut réellement interpréter.
Plan de la séance
Observer et décrire
- tableaux croisés ;
- proportions et %;
- visualisations ;
- intervalles de confiance.
Tester et interpréter
- test du khi² ;
- résidus ;
- taille d’effet ;
- limites des tests ;
- dépendance des observations.
1. OBSERVER ET DECRIRE UNE RELATION
Variables qualitatives : rappel
Une variable qualitative décrit des catégories ou des situations.
Quelques exemples dans l’enquête ERFI ::
age_cat: groupe d’âge ;diplome: niveau de diplôme ;repas_genre: répartition des repas dans le couple ;linge_genre: répartition du linge dans le couple.
Ces variables peuvent être :
- nominales ;
- ordinales ;
- binaires.
Exemple utilisé dans cette séance
Nous allons principalement travailler autour de la question suivante :
la partition des repas dans le couple varie-t-elle selon l’âge ?
Variables mobilisées :
age_cat: catégorie d’âge (18-29 ans ; 30-44 ans ; 45-59 ans ; 60 ans et plus)
repas_genre: répartition des repas dans le couple (Partagé ; Plutôt femme ; Plutôt homme)
Revenir à la question statistique
Question générale :
Les tâches domestiques sont-elles partagées de la même manière selon l’âge ?
Question statistique :
La distribution de
repas_genrevarie-t-elle selonage_cat?
Première étape : observer
Avant de faire un test statistique :
on commence toujours par regarder les données.
La première étape consiste à :
observer ;
décrire ;
comparer.
Pour cela, on utilise principalement :
des tableaux croisés ;
des proportions ;
des graphiques.
Les statistiques ne commencent pas par le calcul d’une p-value
Construire un tableau croisé
Pour étudier une relation entre deux variables qualitatives, on construit un :
tableau de contingence (ou tableau croisé).
Ici age_cat × repas_genre
Lire le tableau
Avant toute interprétation, il faut comprendre ce que représente le tableau.
Questions : - Que représentent les lignes ?
- Que représentent les colonnes ?
- Que signifie une case du tableau ?
Correction — Lire le tableau
- Les lignes représentent les groupes d’âge.
- Les colonnes représentent les modalités de répartition des repas.
- Chaque case correspond au nombre d’individus dans une situation donnée.
Par exemple :
une case peut indiquer combien de personnes de 18–29 ans déclarent que les repas sont “partagés” dans leur couple.
Pourquoi le tableau croisé est central ?
Le tableau croisé permet de :
- décrire une relation ;
- comparer plusieurs groupes ;
- repérer des écarts ;
- préparer l’analyse statistique.
C’est souvent le point de départ de l’analyse de relations entre variables qualitatives.
Mais les effectifs ont une limite
Comparer directement les effectifs peut être trompeur.
Pourquoi ?
Parce que les groupes n’ont pas toujours la même taille.
Exemple :
si le groupe des 30–44 ans contient beaucoup plus d’individus que celui des 18–29 ans, il aura mécaniquement davantage d’effectifs dans plusieurs catégories. Les effectifs bruts ne suffisent donc pas pour comparer correctement les groupes.
Les effectifs bruts ne suffisent donc pas pour comparer correctement les groupes.
Passer aux proportions
Pour comparer correctement les groupes :
on transforme les effectifs en proportions.
Mais attention :
le sens du calcul dépend toujours de la question posée.
Une question essentielle
Que veut-on comparer ici ?
La répartition des repas selon l’âge.
La variable de comparaison est donc :
age_cat
Cela signifie que :
Chaque groupe d’âge doit donc représenter 100%
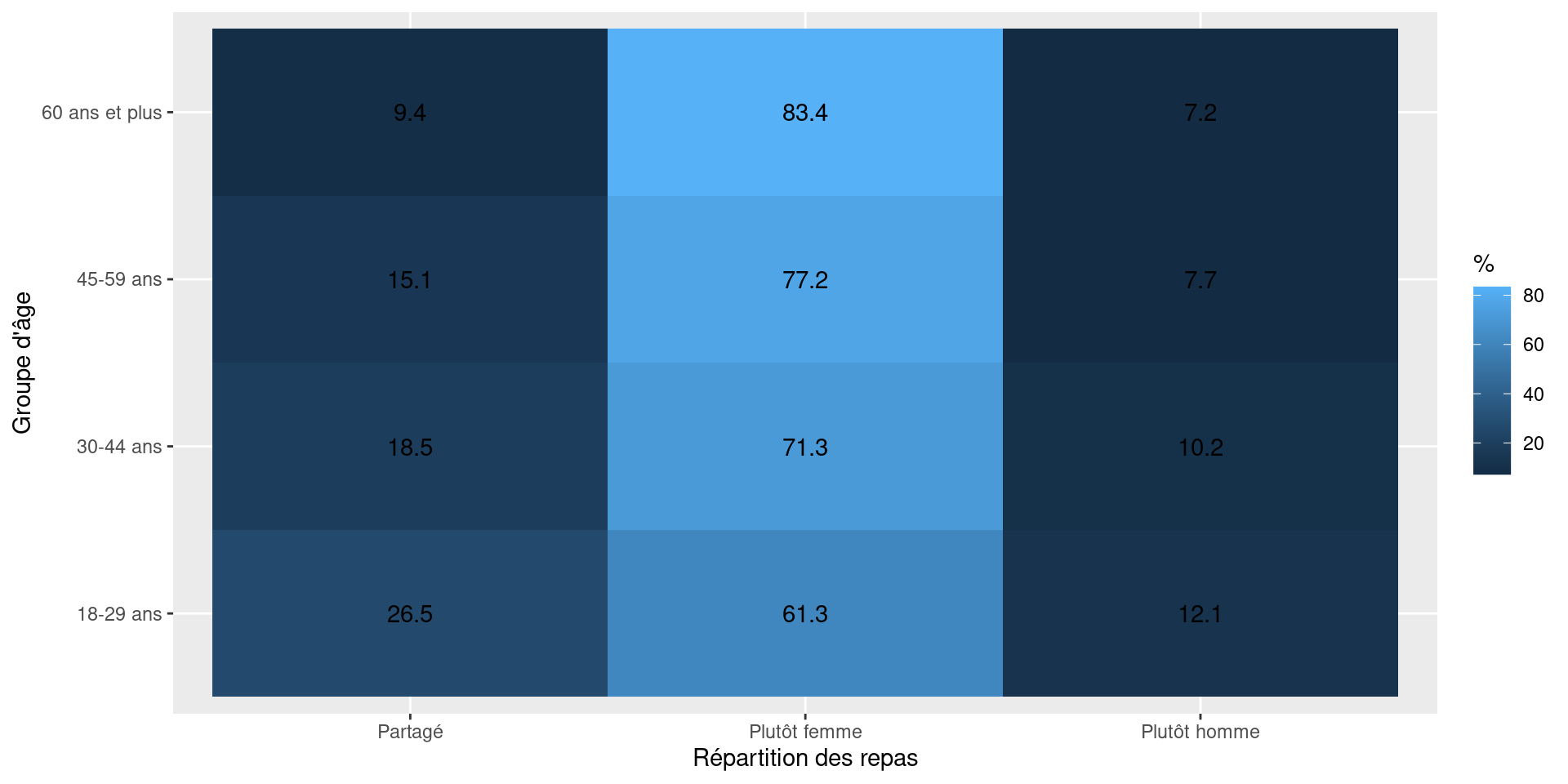
Pourcentages par ligne
On calcule ici les proportions par groupe d’âge.
Plutôt femme Partagé Plutôt homme
18-29 ans 61.921098 25.728988 12.349914
30-44 ans 71.680080 18.259557 10.060362
45-59 ans 77.388535 15.074310 7.537155
60 ans et plus 83.514986 9.332425 7.152589Questions
- Observe-t-on des différences entre groupes d’âge ?
- Quels groupes semblent les plus égalitaires ?
- Les écarts semblent-ils importants ou modestes ?
Correction — Interprétation
On observe que :
la part de situations “Partagé” est plus élevée chez les plus jeunes (environ 27 % chez les 18–29 ans contre 9 % chez les 60 et plus) ;
la part de situations “Plutôt femme” augmente avec l’âge
(environ 61 % chez les 18–29 ans contre plus de 83 % chez les 60 ans et plus) ;les situations “Plutôt homme” restent minoritaires dans tous les groupes.
Les écarts observés semblent relativement marqués, en particulier entre les plus jeunes et les plus âgés.
La répartition des repas semble donc en apparence varier selon l’âge.
Attention au sens de lecture du %
On aurait aussi pu calculer des pourcentages par colonne.
Plutôt femme Partagé Plutôt homme
18-29 ans 8.076063 16.059957 13.872832
30-44 ans 31.879195 38.865096 38.535645
45-59 ans 32.617450 30.406852 27.360308
60 ans et plus 27.427293 14.668094 20.231214Mais cette fois :
on ne répond plus à la même question.
Question
Que change ce calcul ?
Correction — Pourcentages par colonne
Ici, chaque colonne représentent 100 %. On répond à une autre question ici :
parmi les personnes déclarant une situation “Partagé”, quelle est la répartition par âge ?
Ce n’est pas la même logique.
→ On ne compare plus directement les groupes d’âge entre eux.
→ On décrit la composition des modalités de repas_genre.
Point clé à retenir
margin = 1→ % par ligne
→ comparer les groupesmargin = 2→ % par colonne
→ décrire la composition des modalités
Le bon calcul dépend toujours de la question statistique posée.
Exercice — À vous
On change maintenant de variables.
Objectif :
Etudier la relation entre le niveau de diplôme et la répartition du linge dans le couple.
Construire le tableau croisé de
Variables :
diplomelinge_genre
A faire :
Construire le tableau croisé ;
Choisir les bons pourcentages ;
Proposer une interprétation.
Étape 1 — Construire le tableau croisé
diplome×linge_genre
Étape 2 — Réfléchir avant de coder
Questions
- Quelle est la question posée ?
- Que veut-on comparer ?
- Quelle variable définit les groupes de comparaison ?
- Quel pourcentage faut-il calculer ?

Correction — Choisir le bon pourcentage
Ici, on cherche à comparer :
la répartition du linge selon le niveau de diplôme
La variable de comparaison est donc :
diplome
Chaque niveau de diplôme doit représenter 100 %.
Il faut donc calculer des pourcentages par ligne.
Étape 2 — Correction et interprétations
Plutôt femme Partagé Plutôt homme
Au plus brevet 91.051805 6.017792 2.930403
CAP/Bac pro 88.966807 8.041141 2.992052
Bac à Bac+2 80.337079 14.382022 5.280899
Bac+3 ou plus 68.870804 26.144456 4.984741Questions
- La répartition est-elle la même selon le niveau de diplôme ?
- Observe-t-on des écarts ?
- Quelle modalité semble varier le plus ?
- Les écarts sont-ils importants ou modestes ?
Correction — Interprétation
On observe que :
la part de situations “Partagé” augmente nettement avec le diplôme
(6 % au plus le brevet contre plus de 26 % Bac+3 ou plus) ;à l’inverse, la modalité “Plutôt femme” diminue avec le niveau de diplôme (plus de 91 % chez les moins diplômé·es contre environ 69 % chez les plus diplômé·es) ;
les situations “Plutôt homme” restent minoritaires dans tous les groupes.
Les écarts observés semblent relativement marqués, en particulier entre les groupes les moins et les plus diplômés.
Le partage du linge semble donc plus fréquent parmi les personnes les plus diplômées.
Une première limite importante
À ce stade :
Nous avons seulement observé des différences.
Mais plusieurs questions restent ouvertes :
ces écarts sont-ils importants ?
sont-ils robustes ?
pourraient-ils apparaître simplement par hasard ?
Avant de tester statistiquement ces écarts, il est utile de mieux les visualiser
Représenter une relation entre 2 variables avec 1 graphique
Les tableau croisés permettent une lecture précise des effectifs ou pourcentages.
Mais ils deviennent parfois difficiles à lire rapidement.
Les graphiques permettent :
de comparer les groupes ;
de repérer des tendances ;
de visualiser plus facilement les écarts.
Un graphique ne remplace pas le tableau : il aide surtout à voir la structure des données.
Diagramme en barres juxtosées
ggplot(ERFI_couple, aes(x = age_cat, fill = repas_genre)) +
geom_bar(position = "dodge") +
scale_fill_viridis_d(option = "C", end = 0.85) +
labs(
title = "Répartition des repas dans le couple selon l’âge",
subtitle = "Données ERFI (n = 6041 individus en couple)",
x = "Groupe d'âge",
y = "Effectifs",
fill = "Répartition des repas",
caption = "Source : Ined, enquête ERFI-GGS1"
)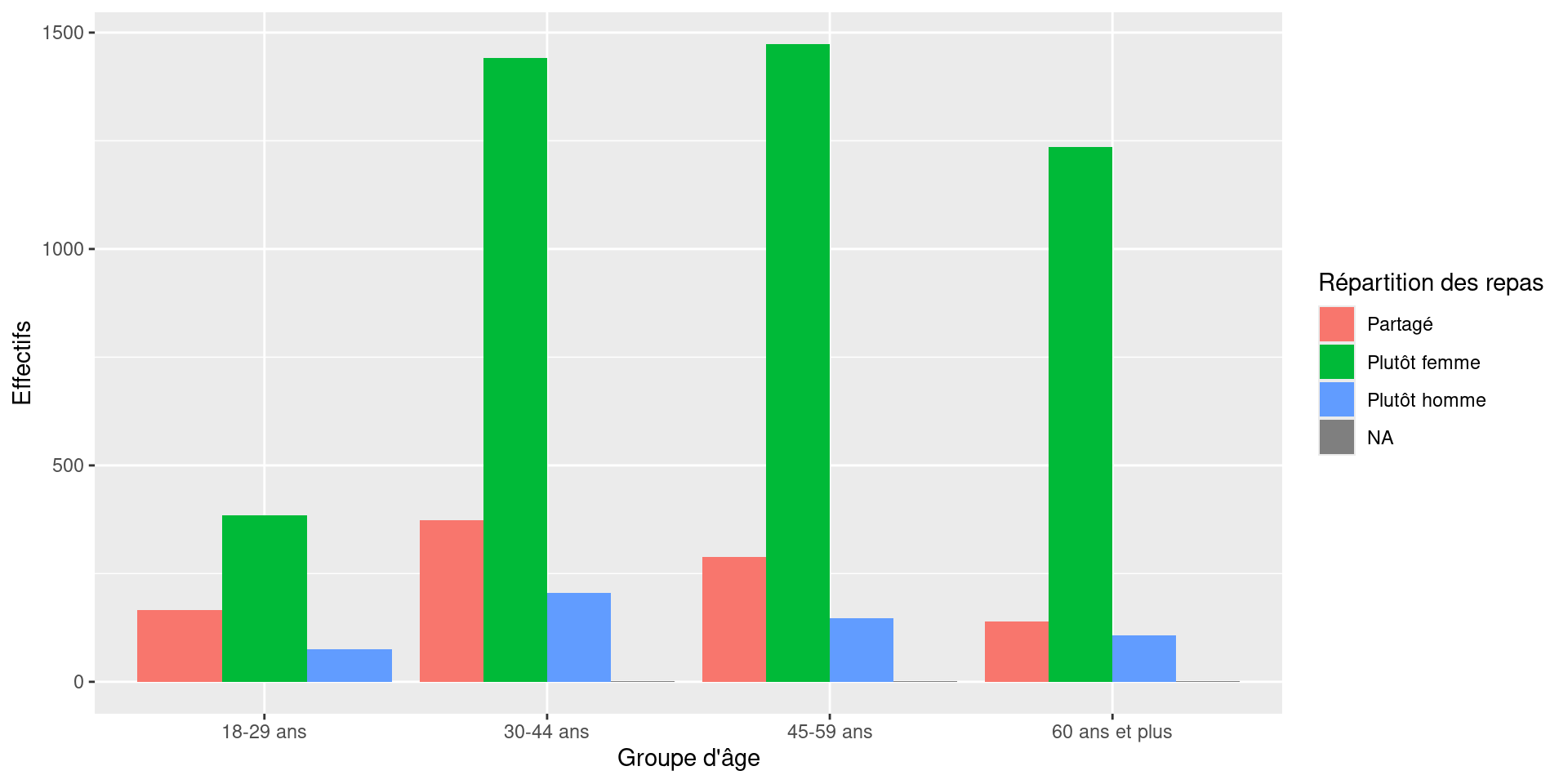
Questions
Que représentent les barres ?
Compare-t-on des effectifs ou des proportions ?
Les groupes sont-ils facilement comparables ?
Correction — Barres juxtaposées
Ici, les graphiques représentent des effectifs
Or :
les groupes d’âge n’ont pas forcément la même taille ;
les hauteurs des barres peuvent donc être trompeuses.
Pour comparer correctement les groupes : il est souvent préférable de raisonner en proportions.
Diagramme en barres empilées à 100 %
ggplot(ERFI_couple, aes(x = age_cat, fill = repas_genre)) +
geom_bar(position = "fill") +
geom_text(stat = "count", aes(
label = round(after_stat(count / tapply(count, x, sum)[x] * 100),1)),
position = position_fill(vjust = 0.5), size = 3, fontface = "bold", colour = "white") +
scale_fill_viridis_d(option = "C", end = 0.85) +
labs( x = "Groupe d'âge",
y = "Proportion",
fill = "Répartition des repas"
)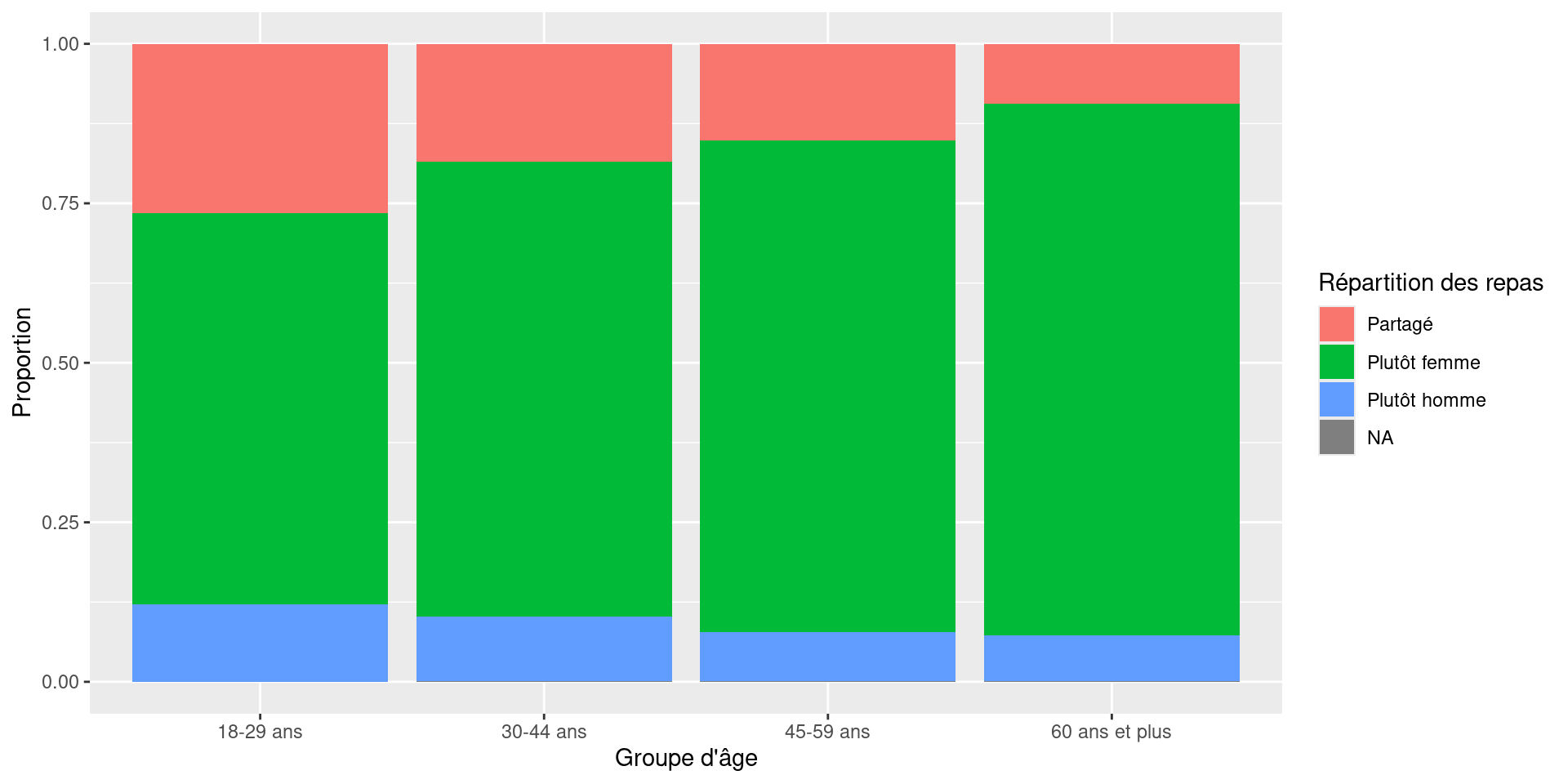
Interpréter le graphique
Questions
La part de “Partagé” est-elle identique selon l’âge ?
La modalité “Plutôt femme” varie-t-elle selon les groupes ?
Correction — Graphiques
On retrouve visuellement ce que montraient déjà les tableaux :
davantage de partage chez les jeunes ;
davantage de prise en charge féminine chez les plus âgés.
Quel graphique choisir ?
Barres juxtaposées : comparer des effectifs.
Barres empilées à 100 % : comparer des proportions.
Pour notre question (La répartition des repas varie-t-elle selon l’âge ?)
→ Graphique empilé à 100 % plus adapté
D’autres visualisations possibles
D’autres représentations peuvent aider à explorer une relation entre deux variables qualitatives :
Mosaic plot
Permet de visualiser :
la taille des groupes ;
la répartition interne des modalités.
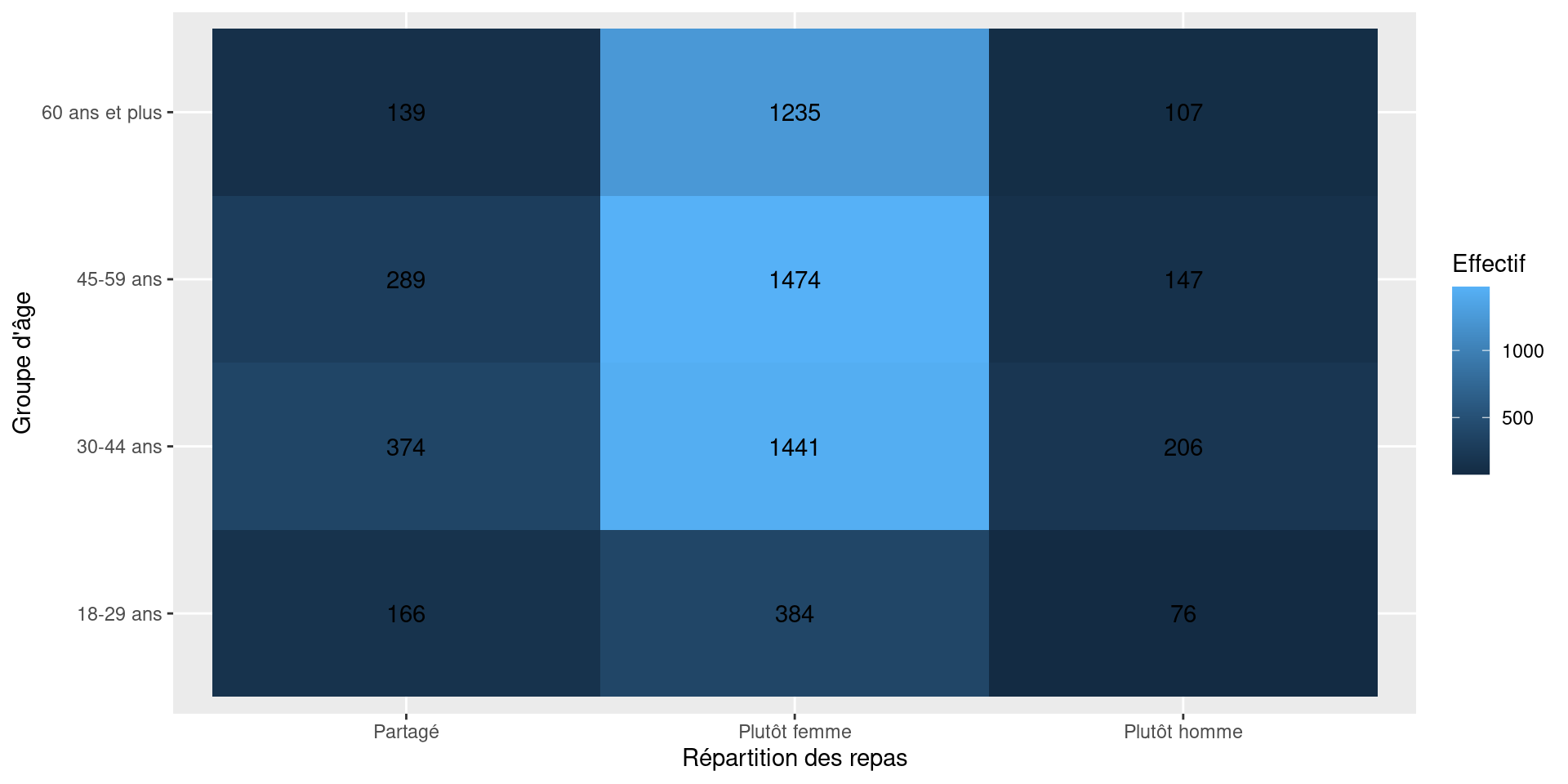
Heatmap du tableau croisé
Permet de :
repérer rapidement les combinaisons fréquentes ;
faire ressortir des structures du tableau.
tab_repas <- table(
ERFI_couple$age_cat,
ERFI_couple$repas_genre
)
tab_repas_prop <- prop.table(tab_repas, margin = 1) * 100
tab_repas_prop_df <- as.data.frame(tab_repas_prop)
ggplot(tab_repas_prop_df, aes(x = Var2, y = Var1, fill = Freq)) +
geom_tile() +
geom_text(
aes(label = round(Freq, 1)),
colour = "white",
fontface = "bold"
) +
scale_fill_viridis_c(option = "C") +
labs(
x = "Répartition des repas",
y = "Groupe d'âge",
fill = "%"
)
Chaque représentation met en avant des informations différentes. Le choix dépend de ce que l’on souhaite montrer.
Limite des visualisations
Les graphiques et tableaux permettent :
- d’explorer ;
- de comparer ;
- de formuler des hypothèses.
Mais :
ils ne permettent pas à eux seuls de savoir si les écarts observés sont compatibles avec le hasard.
Transition
Jusqu’ici :
- nous avons observé des différences ;
- comparé des proportions ;
- visualisé des écarts.
Mais une question reste centrale :
Quelle est l’incertitude autour des proportions calculées à partir de notre échantillon ?

2. ESTIMER UNE PROPORTION ET SON INCERTITUDE
Observer une proportion ne suffit pas
Dans les tableaux et graphiques précédents nous avons observé des proportions.
Par exemple :
- la part de situations “Partagé” chez les 18–29 ans ;
- ou encore la part de partage selon le niveau de diplôme.
Mais une question importante apparaît immédiatement :
Peut-on considérer que ces proportions reflètent exactement la réalité dans la population ?
NON
Pourquoi ?
Parce qu’une proportion calculée sur un échantillon reste :
une estimation.
Pourquoi y a-t-il de l’incertitude ?
Si l’on recommençait l’enquête :
avec d’autres individus ;
dans une autre ville ;
ou à un autre moment
On obtiendrait probablement des résultats légèrement différents.
Autrement dit : |tout échantillon comporte une part de variabilité.
Une proportion est une estimation
En statistique, on ne cherche donc pas seulement à décrire ce que l’on observe. On cherche aussi à évaluer : > l’incertitude autour de ce que l’on observe.
L’idée de l’intervalle de confiance
Plutôt qu’annoncer une valeur unique :
on estime un intervalle de valeurs plausible.
Exemple :
“la proportion de partage des repas est probablement comprise entre 48 % et 56 %”.
Cet intervalle est appelé > un intervalle de confiance.
Intuition générale
Plus les données sont :
- nombreuses ;
- stables ;
- homogènes ;
plus l’incertitude diminue.
À l’inverse :
- petits effectifs ;
- forte variabilité ;
- groupes très hétérogènes
→ incertitude augmente.
Exemple : estimer une proportion
On cherche ici à estimer :
la proportion de situations “Partagé” chez les 18–29 ans.
1-sample proportions test with continuity correction
data: sum(tab_jeunes$repas_genre == "Partagé") out of nrow(tab_jeunes), null probability 0.5
X-squared = 136.4, df = 1, p-value < 2.2e-16
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.2226614 0.2951723
sample estimates:
p
0.2572899 Questions
- Quelle est la proportion observée ?
- L’intervalle est-il large ou étroit ?
- Que signifie concrètement cet intervalle ?
Correction — Interpréter l’intervalle de confiance
On obtient :
- proportion observée : 25,7 %
- IC à 95 % : [22,3 % ; 29,5 %]
Cela signifie que :
la proportion réelle de situations “Partagé” chez les 18–29 ans est plausiblement comprise entre environ 22 % et 30 %.
L’intervalle n’est pas extrêmement large : l’estimation semble donc relativement précise.
Attention à une erreur fréquente
Un IC à 95 % ne signifie pas : > “il y a 95 % de chances que la vraie valeur soit dans cet intervalle”.
Pourquoi ?
Parce que : - la vraie valeur dans la population est fixe (même si on ne la connaît pas). - Ce qui varie, c’est l’intervalle calculé à partir des échantillons.
Point clé
L’intervalle de confiance répond principalement à une question :
avec quelle précision estime-t-on la proportion ?
Taille de l’échantillon et précision
Plus l’échantillon est grand :
- plus l’estimation devient stable.
Et donc :
- plus l’intervalle de confiance devient étroit.
Exemple intuitif
Comparer :
7 situations “Partagé” sur 10 personnes ;
700 situations “Partagé” sur 1000 personnes.
Dans les deux cas :
- proportion = 70 %./
Mais intuitivement :
la seconde estimation paraît beaucoup plus solide ;
car elle repose sur beaucoup plus d’observations.
La variabilité joue aussi un rôle
La largeur d’un intervalle de confiance ne dépend pas uniquement :
de la taille de l’échantillon.
Elle dépend aussi :
de la variabilité des données.
Pour une proportion :
- les intervalles sont souvent plus larges avec des proportions autour de 50 % (incertitude plus grande)
- A l’inverse, avec des proportions proches de 0% ou 100, qd tout le monde donne la même réponse (incertitude plus faible)
Intuition simple
Une proportion autour de 50 % correspond souvent à une situation :
plus “incertaine”, plus mélangée, plus variable.
Une proportion proche de 0 % ou 100 % correspond à une situation :
beaucoup plus homogène et stable.
C’est pour cela que :
les intervalles de confiance sont généralement plus larges autour de 50 %.
Attention aux petits échantillons
Avec de petits effectifs : (ou proportion proche de 0 ou 1)
- l’incertitude est plus grande ;
- les intervalles de confiance deviennent plus larges
- les méthodes d’estimation “classiques” (basées sur l’approximation normale) peuvent devenir moins fiables.
Des méthodes plus adaptées
Pour les petits échantillons, il existe des méthodes plus robustes.
- intervalle de Wilson (souvent plus précis que la méthode classique )
- intervalle exact binomial dit Clopper–Pearson (ne repose pas sur l’approximation normale ; intervalles souvent plus larges que intervalle de Wilson).
En pratique :
les logiciels statistiques utilisent souvent automatiquement les méthodes plus fiables.
Par ex.
prop.test()dans R/Rstudio applique une correction améliorant l’estimation
Une autre approche : le bootstrap
Une autre manière d’estimer l’incertitude consiste à utiliser le bootstrap.
Idée générale :
- recréer artificiellement de nombreux échantillons ;
- à partir des données observées
- puis recalculer la statistique à chaque fois.
On observe alors :
- comment la proportion varie d’un échantillon simulé à l’autre.
Cette variabilité permet d’estimer :
l’erreur standard ;
ou un intervalle de confiance.
Pourquoi le bootstrap est utile ?
Le bootstrap est particulièrement intéressant :
lorsque les formules théoriques sont compliquées ;
pour des statistiques complexes ;
ou lorsque les hypothèses classiques sont fragiles.
C’est aujourd’hui une méthode très utilisée en statistique appliquée.
Comparer plusieurs proportions
On peut aussi comparer :
- plusieurs groupes ;
- plusieurs estimations ;
- plusieurs intervalles de confiance.
Exemple :
comparer la part de “Partagé” selon les groupes d’âge.
Exemple
# A tibble: 4 × 4
age_cat n partage proportion
<fct> <int> <int> <dbl>
1 18-29 ans 583 150 0.257
2 30-44 ans 1988 363 0.183
3 45-59 ans 1884 284 0.151
4 60 ans et plus 1468 137 0.0933Questions
- Les proportions semblent-elles proches ?
- Certains groupes se distinguent-ils nettement ?
- Les écarts semblent-ils importants ?
Mais attention
Observer des écarts entre proportions :
ne suffit pas pour conclure.
Certaines différences peuvent :
être dues au hasard ;
être très faibles ;
apparaître dans un échantillon mais pas dans un autre.
Autrement dit : une différence observée n’est pas forcément une différence statistiquement crédible.
Transition vers la suite
Jusqu’ici, nous avons :
observé des différences entre groupes ;
estimé des proportions ;
évalué leur incertitude grâce aux IC
Mais une question importante reste ouverte :
les différences observées reflètent-elles réellement une relation entre l’âge et la répartition des repas…
…ou pourraient-elles simplement venir du hasard de l’échantillonnage simplement parce que les individus interrogés ne sont pas exactement les mêmes.
C’est précisément ce que vont permettre les tests statistiques.

3. TESTER UNE ASSOCIATION : KHI² ET FISHER
Pourquoi faire un test statistique ?
Les tableaux et graphiques précédents montrent des différences entre groupes.
Mais une question subsiste :
ces écarts traduisent-ils réellement une relation entre les variables……ou pourraient-ils simplement être dus au hasard de l’échantillonnage ?
Les tests statistiques servent justement à évaluer :
- si les écarts observés paraissent compatibles avec le hasard.
La logique générale d’un test
Un test statistique commence toujours par une hypothèse de départ :
“Et s’il n’y avait en réalité aucune relation entre les variables dans la population ?”
Cette hypothèse est appelée : hypothèse nulle (H0).
Hypothèse nulle et hypothèse alternative
Dans notre exemple :
H0 : la répartition des repas ne varie pas selon l’âge.
→age_catetrepas_genresont indépendantes.
Hypothèse alternative :
H1 : les deux variables sont liées / associées et donc pas indépendantes.
Ce que fait réellement un test
Question :
Que fait réellement un test statistique selon vous ?
Il prouve que H0 est vraie.
Il prouve que H1 est vraie.
Il évalue si les données sont compatibles avec H0.
Correction
Un test statistique ne prouve jamais qu’une hypothèse est vraie.
Il évalue plutôt :
si les données observées paraissent compatibles avec l’hypothèse nulle (indépendance des var)
La p-value
La p-value correspond à :
la probabilité d’observer des écarts au moins aussi importants que ceux observés dans notre échantillon, si H0 était vraie.
→ si le hasard était la seule explication, ce que l’on observe serait-il surprenant ?
Interpréter une p-value (elle est calculée à partir des données)
p-value faible = les données sont peu compatibles avec H0
→ on peut rejeter H0 –> les écarts observés paraissent difficiles à expliquer uniquement par le hasard
p-value élevée = les écarts observés restent compatibles avec H0 –> les différences observées pourraient raisonnablement venir du hasard –> on ne rejette pas H0
Le seuil de 5 %
Souvent on utilise le seuil de 5% : (ça dépend des disciplines)
On parle alors :
de résultat “statistiquement significatif”.
Comment comprendre ce seuil de 5 % ?
Le seuil de 5 % correspond à :
- un niveau de risque accepté avant de rejeter H0
Autrement dit :
- même si H0 était vraie, on accepterait qu’environ 5 % des tests conduisent malgré tout, par hasard, à conclure à une association.
Attention la p-value n’est pas “la probabilité que H0 soit vraie”. (confusion fréquente)
Attention aux mauvaises interprétations
Une p-value ne dit pas :
- que la relation est forte ;
- que la relation est importante scientifiquement ;
- que la relation est causale ;
- que H1 est “vraie”.
Elle indique seulement : si les données observées sont compatibles avec H0.
Petit exercice
On compare deux groupes.
Le test donne :
Questions
- Peut-on rejeter H0 au seuil de 5 % ?
- Peut-on dire que la relation est forte ?
- Peut-on conclure à une relation causale ?
Correction
Avec une p-value de 0.03, les données sont peu compatibles avec HO, on rejette H0 en prenant un risque de 5 % ;
les écarts observés paraissent peu compatibles avec l’hypothèse du hasard.
Mais :
cela ne dit pas si l’effet est fort ;
cela ne permet pas de conclure à une relation causale.
Retour à notre question
Nous voulons tester :
la répartition des repas varie-t-elle selon l’âge ?
Variables étudiées :
age_catrepas_genre
Comme les deux variables sont qualitatives :
on utilise un test du khi² d’indépendance.
Principe du test du khi²
Le test du khi² compare :
- ce que l’on observe dans le tableau croisé ;
- à ce que l’on attendrait s’il n’existait aucune relation entre les 2 variables
Autrement dit :
observé vs attendu sous indépendance.;
- à ce que l’on attendrait s’il n’existait aucune relation.
Étape 1 — Les effectifs observés
Plutôt femme Partagé Plutôt homme
18-29 ans 361 150 72
30-44 ans 1425 363 200
45-59 ans 1458 284 142
60 ans et plus 1226 137 105Une question importante
Si les variables étaient indépendantes :
à quoi ressemblerait notre tableau ?
Le test va justement construire :
- ce tableau “théorique” attendu sous H0.
Étape 2 — Les effectifs attendus
Si les variables étaient indépendantes :
chaque groupe d’âge aurait globalement la même répartition des repas.
Le test calcule donc :
les effectifs “attendus” dans chaque case si HO était vraie
Formule des effectifs attendus
Pour chaque case :
Exemple avec nos données
Plutôt femme Partagé Plutôt homme
18-29 ans 361 150 72
30-44 ans 1425 363 200
45-59 ans 1458 284 142
60 ans et plus 1226 137 105Question
- Quel serait l’effectif attendu des 18-29 ans qui seraient dans la catégorie “Plutôt femme” si les variables étaient indépendantes ?
Les totaux nécessaires
18-29 ans 30-44 ans 45-59 ans 60 ans et plus
583 1988 1884 1468
Plutôt femme Partagé Plutôt homme
4470 934 519 [1] 5923total ligne 18-29 ans = 583
total colonne “Plutôt femme” = 4470
total général = 5923
Calcul de l’effectif attendu
Dans les données :
attendu sous indépendance = 440
observé = 361
Il existe donc :
- un écart important entre ce qu’on observe et ce qu’on attendrait s’il n’y avait aucun lien
Étape 3 — Mesurer l’écart
Le khi² mesure l’écart entre :
les effectifs observés ;
et les effectifs attendus s’il n’y a aucun lien cad sous l’hypothèse d’indépendance
Pour chaque case du tableau, on calcule par ex. ici pour une case :
→ ici contribution ≈ 14.18
On parle de « contribution au khi² total» - chaque case apporte une part du khi² total
Le χ² final correspond donc à la somme des contributions de toutes les cases du tableau.
Intuition
Si observé et attendu sont très proches :
la contribution est faible ;
la case est compatible avec l’hypothèse d’indépendance.
Si observé et attendu sont très différents :
la contribution devient grande ;
la case “pousse” le χ² vers le haut ;
elle suggère davantage une association entre les variables.
Dans notre exemple où l’écart est relativement important. La case contribue donc fortement au χ² total.
PAssons à la pratique : réaliser le test du khi²
Pearson's Chi-squared test
data: table(ERFI_couple$age_cat, ERFI_couple$repas_genre)
X-squared = 135.07, df = 6, p-value < 2.2e-16Questions
- Quelle est la p-value ?
- Peut-on rejeter H0 ?
- Que peut-on conclure ?
Correction — Interprétation
On obtient :
- χ² = 145,74
- p-value < 2,2e-16
La p-value est très inférieure à 0,05.
On rejette l’hypothèse d’indépendance.
Il existe donc :
une association statistiquement significative entre l’âge et la répartition des repas.
Mais attention
Le test indique :
qu’une association existe probablement.
Mais il ne dit pas :
- où se situent les écarts ;
- si la relation est forte ;
- si elle est importante scientifiquement.
Conditions du test du khi²
Le test du khi² suppose notamment :
- des variables qualitatives ;
- des observations indépendantes ;
- des effectifs attendus suffisants.
Règle classique :
au moins 80 % des cases doivent avoir un effectif attendu ≥ 5.
Vérifier les effectifs attendus
Plutôt femme Partagé Plutôt homme
18-29 ans 439.9814 91.93348 51.08509
30-44 ans 1500.3140 313.48843 174.19754
45-59 ans 1421.8268 297.08864 165.08459
60 ans et plus 1107.8778 231.48945 128.63279Questions
- Les effectifs attendus semblent-ils suffisants ?
- Certaines cases posent-elles problème ?
- Le test paraît-il utilisable ici ?
Correction
Ici :
tous les effectifs attendus sont supérieurs à 5.
Le test du khi² semble donc adapté.
Que faire si les effectifs sont faibles ?
Lorsque certaines cases contiennent :
- très peu d’observations ;
- ou des effectifs attendus trop faibles ;
→ le khi² devient moins fiable
Une alternative : le test exact de Fisher
Dans ce cas :
on peut utiliser le test exact de Fisher.
Particulièrement utile :
- pour les petits effectifs ;
- pour les tableaux 2 × 2.
Principe du test de Fisher
Le test de Fisher calcule directement :
- la probabilité d’obtenir un tableau au moins aussi extrême que celui observé, si les variables étaient indépendantes.
Exemple de code
Point important
Le choix du test dépend :
- du type de variables,
- de la structure des données ;
- de la taille des effectifs ;
- et des hypothèses nécessaires au test.
Exemples
|——————————————–|—————————-| | Situation | Test souvent utilisé | | variables qualitatives + effectifs suffisants | khi² | | petits effectifs / cases rares | Fisher | | observations non indépendantes | autres méthodes nécessaires | | données ordonnées, spatiales répétées | McNemar, Stuart-Maxwell… |
Une idée essentielle
Le test statistique ne remplace jamais :
- l’interprétation ;
- la connaissance du terrain et des données ;
- le raisonnement scientifique.
Une p-value ne suffit jamais à elle seule.
Exemple 1 — “Significatif” mais peu important
Imaginons une très grande enquête sur plusieurs dizaines de milliers de personnes.
On observe :
51 % de pratique du vélo dans un groupe ;
contre 49 % dans un autre.
Le test donne : p-value < 0.001
Statistiquement :
- la différence est “significative”.
Mais concrètement :
- l’écart est très faible (2 points seulement).
Avec un très grand échantillon :
- même de petites différences peuvent devenir significatives.
La question devient alors :
- cette différence est-elle réellement importante scientifiquement ou socialement ?
Transition vers la suite
Le khi² nous indique :
qu’une association existe probablement.
Mais une nouvelle question apparaît :
- quelles cases du tableau contribuent le plus à cette association ?
Pour répondre à cette question : il faut regarder les résidus.

4. COMPRENDRE LES ÉCARTS : LES RÉSIDUS DU χ²
Les résidus
Dans notre exemple :
quelles catégories d’âge contribuent le plus à l’association observée ?
Pour répondre, on examine les résidus du tableau croisé.
Les résidus comparent :
- ce qui est observé ;
- à ce qui serait attendu sous indépendance.
Intuition
Pour chaque case :
résidu positif → plus de cas observés que prévu ;
résidu négatif → moins de cas observés que prévu.
Et :
plus le résidu est éloigné de 0,
plus la case contribue au χ².
Calculer les résidus
Plutôt femme Partagé Plutôt homme
18-29 ans -3.7653713 6.0560430 2.9262328
30-44 ans -1.9443964 2.7963781 1.9549704
45-59 ans 0.9593208 -0.7593665 -1.7966721
60 ans et plus 3.5488344 -6.2103734 -2.0837188Questions
- Quelles cases présentent les résidus les plus élevés ?
- Où observe-t-on plus de cas que prévu ?
- Où observe-t-on moins de cas que prévu ?
Correction — Interprétation
Les écarts les plus marqués concernent :
- 18–29 ans / “Partagé” → résidu positif important ;
- 60 ans et plus / “Partagé” → résidu négatif important ;
- 60 ans et plus / “Plutôt femme” → résidu positif.
Cela signifie que :
- les plus jeunes déclarent plus souvent une situation “Partagé” que ce qui serait attendu sous indépendance ;
- les plus âgés déclarent moins souvent une situation “Partagé” ;
- les plus âgés déclarent plus souvent une situation “Plutôt femme”.
Les résidus permettent donc de localiser l’association.
Une idée importante
Le χ² global résume :
tous les écarts du tableau.
Les résidus permettent de comprendre :
quelles cases produisent ces écarts.
Différents types de résidus
Plusieurs types de résidus existent :
- résidus bruts ;
- résidus standardisés ;
- résidus ajustés.
Le tableau affiché par chisq.test() correspond à des résidus standardisés.
Pourquoi standardiser ?
Toutes les cases du tableau :
- n’ont pas les mêmes effectifs ;
- n’ont pas les mêmes variabilités.
La standardisation permet donc de rendre les écarts comparables entre cases.
Point pratique
En pratique :
- les résidus proches de 0 → peu de contribution ;
- résidus fortement positifs ou négatifs → forte contribution à l’association.
Visualiser les résidus
Une heatmap permet de visualiser rapidement :
les cellules qui contribuent le plus au χ².
test_khi2 <- chisq.test(tab_obs)
residus <- as.data.frame(test_khi2$residuals)
ggplot(
residus,
aes(x = Var2, y = Var1, fill = Freq)
) +
geom_tile(color = "white") +
geom_text(
aes(label = round(Freq, 2)),
fontface = "bold",
colour = "white"
) +
scale_fill_viridis_c(
option = "C",
direction = -1
) +
labs(
title = "Résidus du test du khi²",
subtitle = "Écarts entre effectifs observés et attendus",
x = "Répartition des repas",
y = "Groupe d'âge",
fill = "Résidu"
) +
theme_minimal()
Questions
- Quelles cases ressortent le plus ?
- Où observe-t-on des surreprésentations ?
- Où observe-t-on des sous-représentations ?
Correction — Heatmap
Les couleurs les plus intenses correspondent :
aux cases qui contribuent le plus au χ².
On retrouve notamment :
- davantage de “Partagé” chez les plus jeunes ;
- davantage de “Plutôt femme” chez les plus âgés.
Attention à l’interprétation
Les résidus permettent :
- d’identifier des écarts ;
- de localiser l’association.
Mais :
ils ne permettent toujours pas de conclure à une causalité.
Comment rédiger une interprétation ?
On peut écrire :
On observe une association statistiquement significative entre le groupe d’âge et la répartition des repas. Les jeunes déclarent plus souvent une situation partagée que ce qui serait attendu en cas d’indépendance, tandis que les personnes les plus âgées déclarent plus souvent une répartition plutôt féminine. {.blockquote}
Important
Les résidus aident à répondre à la question : “où se situe l’association ?”
Mais:
cette association est-elle forte ou faible ?
Quelle est l’intensité globale de la relation ?
Pour cela, on utilise une taille d’effet.
5. MESURER L’INTENSITÉ D’UNE RELATION : LE V DE CRAMER
Pourquoi la question de l’intensité est importante
Le test du khi² nous indique :
- s’il existe probablement une association entre les variables.
Mais il ne dit pas :
- si cette association est forte ou faible.
Et c’est important.
Pourquoi ?
Parce qu’avec de très grands échantillons : même de petites différences peuvent devenir statistiquement significatives.
Une nouvelle question
Après avoir testé l’existence d’une association :
- il faut maintenant mesurer son intensité.
Autrement dit :
- les variables sont-elles faiblement liées ou fortement liées ?
Le V de Cramer
Pour deux variables qualitatives, une mesure classique de l’intensité de la relation est :
le V de Cramer.
Le V de Cramer mesure :
la force globale de l’association entre les variables.
Intuition du V de Cramer
Le V de Cramer repose sur la même logique que le khi², il compare :
ce que l’on observe ;
à ce que l’on attendrait s’il n’existait aucun lien.
petits écarts entre observé et attendu → V proche de 0 –> relation faible
grands écarts → V plus élevé –> relation plus forte
Échelle de lecture
Le V de Cramer varie entre :
0 → absence de relation ;
1 → relation très forte.
Repères souvent utilisés :
- ~ 0,1 → relation faible ;
- ~ 0,3 → modérée ;
- ~ 0,5 → forte.
Ces seuils restent indicatifs.
Important : le contexte compte
L’interprétation dépend aussi :
- du domaine scientifique ;
- du contexte ;
- du phénomène étudié.
Dans certaines disciplines :
une faible association peut déjà être importante (santé, étude de phénomènes rares)
Calculer le V de Cramer
Cramer's V (adj.) | 95% CI
--------------------------------
0.10 | [0.09, 1.00]
- One-sided CIs: upper bound fixed at [1.00].Questions
- Quelle est la valeur du V ?
- Est-elle proche de 0 ou de 1 ?
- Comment interpréter cette valeur ?
Correction — Interprétation
On obtient :
V ≈ 0,11
Cette valeur est relativement proche de 0.
Cela suggère que :
l’association entre l’âge et la répartition des repas existe…
…mais qu’elle reste globalement faible.
Une idée importante
On peut donc avoir :
une association statistiquement significative ;
mais une intensité faible.
C’est très fréquent avec les grands échantillons.
Relier les résultats
Nous pouvons maintenant distinguer plusieurs niveaux d’analyse :
- le khi² → existe-t-il une association ?
- les résidus → où se situent les écarts ?
- le V de Cramer → quelle est l’intensité globale de la relation ?
Exemple de formulation complète
On observe une association statistiquement significative entre l’âge et la répartition des repas. Les plus jeunes déclarent plus souvent une situation partagée, tandis que les plus âgés déclarent plus souvent une répartition plutôt féminine. Toutefois, la taille d’effet (V de Cramer ≈ 0,11) indique que cette association reste faible.
À vous — Appliquer le test du khi²
On reprend l’exercice précédent :
La répartition du linge varie-t-elle selon le niveau de diplôme ?
Variables : diplome et linge_genre
Étape 1 — Réaliser le test du khi²
Plutôt femme Partagé Plutôt homme
Au plus brevet 1740 115 56
CAP/Bac pro 1903 172 64
Bac à Bac+2 715 128 47
Bac+3 ou plus 677 257 49
Pearson's Chi-squared test
data: table(ERFI_couple$diplome, ERFI_couple$linge_genre)
X-squared = 326.48, df = 6, p-value < 2.2e-16Étape 2 — Vérifier les effectifs attendus
Plutôt femme Partagé Plutôt homme
Au plus brevet 1624.4952 216.8145 69.69036
CAP/Bac pro 1818.3125 242.6824 78.00507
Bac à Bac+2 756.5676 100.9759 32.45653
Bac+3 ou plus 835.6247 111.5273 35.84805Question :
- les conditions du test semblent-elles respectées ?
Étape 3 — Interpréter la p-value
Résultats : χ² = 325,16 ; ddl = 6 ; p-value < 0,001
Conclusion :
- on rejette l’hypothèse d’indépendance.
La répartition du linge semble donc varier selon le niveau de diplôme.
Étape 4 — Localiser les écarts
Plutôt femme Partagé Plutôt homme
Au plus brevet 2.865767 -6.914572 -1.639942
CAP/Bac pro 1.986026 -4.537245 -1.585710
Bac à Bac+2 -1.511232 2.689324 2.552802
Bac+3 ou plus -5.487381 13.774983 2.196632Les résidus montrent que l’association est surtout portée par certaines catégories.
L’écart le plus marqué concerne :
- la modalité “partagé” chez les plus diplômé·es.
Étape 5 — Interpréter avec prudence
Les résultats mettent en évidence une association statistiquement significative entre le niveau de diplôme et la répartition du linge au sein du couple.
Les personnes les plus diplômées déclarent plus souvent une organisation partagée.
Mais attention :
- cette relation ne peut pas être interprétée automatiquement comme une relation causale. On ne peut affirmer que le niveau de diplôme influence la manière dont le partage du linge est réparti dans le couple”
D’autres facteurs peuvent intervenir :
activité professionnelle ;
revenus ;
organisation familiale ;
temps disponible ; etc. ,
sans que cette relation ne puisse être interprétée comme causale. {.blockquote}
Petit reflexe de vocabulaire
Les statistiques descriptives et les tests d’association ne suffisent généralement pas à démontrer une causalité.
| Formulation prudente | Formulation causale |
| est associé à | provoque |
| varie selon | entraîne |
| est lié à | influence |
| est plus fréquent chez | explique |
6. GRANDS ÉCHANTILLONS : SIGNIFICATIF ≠ IMPORTANT
Une situation très fréquente aujourd’hui
Dans de nombreuses disciplines :
- sciences sociales numériques ;
- informatique ;
- écologie instrumentée ;
- santé ;
- données issues de capteurs ;
- plateformes numériques ;
les jeux de données deviennent :
de+ en + volumineux.
Une conséquence importante
Quand la taille de l’échantillon augmente :
- les tests statistiques deviennent extrêmement sensibles.
Résultat :
- même des écarts très faibles peuvent devenir statistiquement significatifs.
Exemple intuitif
Imaginons :
- Groupe A : 52 % “Partagé”
- Groupe B : 50 % “Partagé”
Échantillon :
15 000 individus.
Question
Un écart de seulement 2 points :
est-ce forcément “négligeable” ?
ou un très grand échantillon comme celui-ci peut-il rendre cet écart statistiquement détectable ?
Correction
Oui.
Avec un très grand échantillon : même un écart minime peut produire une p-value très faible.
Une idée essentielle
Le test du Khi2 répond uniquement à cette question :
les écarts observés sont-ils compatibles avec l’hypothèse du hasard ?
Mais il ne répond pas à :
- la différence est-elle importante ?
Significatif ≠ important
Une association peut être détectée statistiquement par le khi²…
…tout en restant relativement faible en pratique selon le V de Cramer.
Le khi² permet de savoir : “existe-t-il probablement une association ?”
Le V de Cramer permet plutôt de savoir : “cette association est-elle forte ou faible ?”
Pourquoi cela arrive-t-il ?
Quand l’échantillon augmente :
l’incertitude diminue ;
les estimations deviennent plus stables ;
le “bruit” statistique diminue.
Le test devient alors capable de détecter :
- des différences de plus en plus petites.
Une autre difficulté des grands jeux de données
Avec beaucoup de variables :
- il devient très facile de trouver des relations statistiquement “significatives”.
Même lorsqu’aucune relation réelle n’existe.
Pourquoi cela arrive-t-il ?
Chaque test statistique comporte un risque de faux positif.
Par exemple, le plus souvent le seuil de significativité fixé avant le test est de 5%.
Cela signifie que :
- même si aucune relation réelle n’existe dans la population, on accepte qu’environ 5 % des tests puissent devenir significatifs “simplement par hasard”.
Une idée importante
Plus on teste de relations :
plus on augmente le risque de trouver des associations illusoires.
Le risque augmente lorsque :
on teste énormément de variables ;
on multiplie les regroupements ;
on essaie plusieurs traitements ;
on cherche “quelque chose de significatif”.
Exploration vs confirmation
Analyse exploratoire
Objectif :
regarder ce que racontent les données ;
faire émerger des pistes intéressantes ;
identifier des relations possibles ;
générer des hypothèses.
Analyse confirmatoire
- tester une hypothèse prévue avant l’analyse ;
- vérifier si les résultats observés sont compatibles avec cette hypothèse ;
- avec une interprétation plus rigoureuse.
Explorer des données n’est pas un problème.
Le problème apparaît lorsque :
- des résultats trouvés “par exploration” sont ensuite présentés comme s’ils avaient été prévus et confirmés dès le départ.
Une formulation plus honnête serait :
- “Une association exploratoire a été observée entre telle var et telle var. Cette relation mériterait d’être testée dans une nouvelle étude.”
Deux termes importants
Data dredging: Explorer massivement les données à la recherche de résultats significatifs.
p-hacking : Multiplier les analyses jusqu’à obtenir une p-value “acceptable”.
Comment limiter ce risque ?
Lorsque de nombreux tests sont réalisés :
certaines méthodes permettent de réduire le risque de faux positifs.
Correction de Bonferroni
Principe :
rendre le seuil plus strict lorsqu’on réalise beaucoup de tests.
Exemple :
- 20 tests avec un seuil global = 0,05.
On utilise alors :
→ seuil corrigé = 0,0025.
Avantages et limites
Avantage
- méthode simple ;
- réduit fortement les faux positifs.
Limite du nouveau seuil
très conservatrice ; le test devient plus exigeant
peut aussi rendre plus difficile la détection de vrais effets.
Une autre approche : FDR
La False Discovery Rate cherche à contrôler
la proportion de faux positifs parmi les résultats déclarés significatifs.
Méthode classique : Benjamini–Hochberg.
Intuition
Contrairement à Bonferroni :
on n’essaie pas d’éliminer tous les faux positifs.
On accepte plutôt :
qu’une petite partie des découvertes puisse être fausse.
Cette approche est souvent plus adaptée :
- aux grands jeux de données ;
Mais attention
Ces corrections ne “réparent” pas :
une mauvaise question de recherche ;
une stratégie d’analyse fragile ;
une interprétation abusive.
Elles permettent seulement :
de limiter certains risques statistiques.
Validation externe
Lorsqu’un résultat apparaît, il est important de vérifier
> s’il se retrouve ailleurs.
Par exemple :
dans un autre échantillon ;
sur une autre période ;
dans une autre ville ;
dans un autre jeu de données
Ce qu’il faut retenir
Lorsque beaucoup de tests sont réalisés :
les faux positifs deviennent plus fréquents ;
la prudence devient essentielle ;
les tailles d’effet et les IC deviennent encore plus importants ;
la validation externe devient particulièrement utile.
Une idée méthodologique centrale
Les statistiques ne servent pas à “produire des p-values”.
Elles servent plutôt :
à quantifier l’incertitude
autour d’un raisonnement empirique.
Transition vers la suite
Jusqu’ici, nous avons supposé que les observations étaient indépendantes.
Mais dans la vie réelle, on peut avoir :
mesures répétées dans le temps ;
individus regroupés
et dans ce cas, que se passe-t-il :
lorsque les observations se ressemblent ou dépendent les unes des autres ?

7. QUAND LES OBSERVATIONS NE SONT PLUS INDEPENDANTES
Une hypothèse souvent oubliée
Depuis le début, nous avons supposé que les observations étaient indépendantes.
Cette hypothèse est essentielle :
- pour les intervalles de confiance ;
- pour le khi² ;
- pour de nombreuses méthodes statistiques.
Mais dans les données réelles…
Les observations sont souvent :
- regroupées ;
- liées ;
- proches dans l’espace ;
- proches dans le temps ;
- produites par les mêmes individus.
Elles ne sont donc pas totalement indépendantes.
Exemples
| Domaine | Exemple |
|---|---|
| Écologie | plusieurs oiseaux observés sur un même site |
| Informatique | nombreuses simulations issues du même modèle |
| Réseaux sociaux | plusieurs messages du même utilisateur |
| Santé | plusieurs cellules provenant du même patient |
| Géographie | capteurs proches spatialement |
| Enquête | plusieurs réponses d’un même ménage |
Une question importante
Supposons 500 observations.
Mais :
- provenant de seulement 3 sites ;
- ou de 5 utilisateurs ;
- ou de 2 laboratoires.
A-t-on réellement 500 observations indépendantes ?
Réponse
Pas forcément.
Les observations issues :
- d’un même site ;
- d’un même individu ;
- d’un même contexte ;
ont souvent tendance
à se ressembler.
Une idée essentielle
Le problème n’est pas seulement :
combien d’observations possède-t-on ?
Mais aussi :
combien d’informations réellement indépendantes possède-t-on ?
La pseudo-réplication
On parle de pseudo-réplication lorsque :
des observations dépendantes
sont traitées comme indépendantes.
Exemple
Imaginons :
- 50 oiseaux observés dans une seule forêt ;
- comparés à 50 oiseaux observés dans une prairie.
Le problème :
on n’a pas réellement 50 forêts et 50 prairies.
on a surtout 1 forêt et 1 prairie.
Pourquoi est-ce un problème ?
Les oiseaux d’un même site partagent :
- le même environnement ;
- les mêmes conditions ;
- le même observateur ;
- les mêmes contraintes locales.
Les observations sont donc corrélées.
Conséquence
Si on ignore cette dépendance :
- on surestime la quantité d’information disponible ;
- on sous-estime l’incertitude ;
- les intervalles de confiance deviennent trop étroits ;
- les variances sont sous-estimées ;
- les p-values deviennent artificiellement petites.
On risque alors de conclure trop facilement qu’une association existe
Taille d’échantillon effective
Dans ce cas :
la taille d’échantillon “réelle” devient plus petite que le nombre brut d’observations.
Autrement dit :
beaucoup de données
ne signifie pas forcément
beaucoup d’information nouvelle.
Autocorrélation
On parle d’autocorrélation lorsque :
des observations proches
dans l’espace,
dans le temps
ou dans un même groupe
tendent à se ressembler.
Pourquoi l’indépendance est importante ?
La plupart des méthodes classiques supposent que chaque observation apporte une information nouvelle.
Mais si les observations sont liées / se ressemblent :
- même individu observé plusieurs fois ;
- oiseaux issus d’un même site ;
- capteurs proches dans l’espace ;
- messages produits par un même compte ;
alors information réellement dispo
est plus faible qu’elle n’en a l’air.
Conséquence pour les IC
Si la taille d’échantillon effective est plus faible
l’incertitude réelle est plus grande.
Donc :
- les erreurs standards devraient être plus grandes ;
- les intervalles de confiance devraient être plus larges ;
- les conclusions devraient être plus prudentes.
Que peut-on faire ?
Lorsque les données sont dépendantes, plusieurs approches existent :
- agréger les données ;
- tenir compte des groupes ;
- utiliser des modèles adaptés.
Ouvertures vers d’autres méthodes
| Méthode | Idée générale |
|---|---|
| Modèles mixtes | tenir compte des groupes ou répétitions (individus, sites, classes…) |
| Modèles hiérarchiques / multiniveaux | représenter des données organisées à plusieurs niveaux |
| Modèles spatiaux | prendre en compte la proximité géographique |
| Modèles temporels | modéliser les dépendances dans le temps |
| Bootstrap par blocs | rééchantillonner des groupes/blocs plutôt que des observations isolées |
Idée commune
Toutes ces méthodes cherchent à mieux représenter la dépendance entre observations afin d’estimer plus correctement l’incertitude.
Le choix d’une de ces méthodes dépend surtout :
- du protocole de collecte ;
- de la structure des données ;
- et du type de dépendance attendu.
Nous ne détaillerons pas ces méthodes ici, mais elles sont importantes dans beaucoup de recherches.
Point méthodologique essentiel
Avant d’appliquer un test toujours se demander :
- qu’est-ce qu’une observation ?
- quelles observations peuvent se ressembler ?
- l’hypothèse d’indépendance est-elle plausible ?
8. CONCLUSION : INTERPRÉTER AVEC PRUDENCE
Revenir à la question de départ
Tout au long de cette séance, nous avons essayé de répondre à une question :
Quand deux catégories semblent liées, comment savoir si cette relation est :
- réelle ?
- importante ?
- robuste ?
- interprétable ?
Ce que nous avons vu
Pour étudier une relation entre variables qualitatives, nous avons appris à :
- observer et comparer ;
- raisonner en proportions ;
- quantifier l’incertitude ;
- tester une association ;
- interpréter les écarts ;
- discuter les limites des résultats.
Une démarche statistique
Observer
→ Comparer
→ Estimer l’incertitude
→ Tester
→ Interpréter
→ Discuter les limites
Les statistiques servent surtout à raisonner rigoureusement à partir de données imparfaites.
Une idée essentielle
Une analyse statistique :
ne se résume jamais à une p-value.
Interpréter correctement un résultat demande de réfléchir à :
- la taille des écarts ;
- l’incertitude ;
- le contexte scientifique ;
- la qualité des données ;
- les hypothèses des méthodes utilisées.
Ce qu’un test statistique ne dit pas
Un test significatif :
- ne prouve pas une causalité ;
- ne garantit pas une relation forte ;
- ne garantit pas une relation importante ;
- ne garantit pas une relation robuste.
Une interprétation statistique n’est jamais automatique.
Ce qu’il faut toujours vérifier
Avant de conclure :
- les variables sont-elles bien définies ?
- les groupes sont-ils comparables ?
- les effectifs sont-ils suffisants ?
- les observations sont-elles indépendantes ?
- les résultats sont-ils scientifiquement intéressants ?
- les conclusions semblent-elles robustes ?
Une idée importante
Les statistiques ne remplacent pas :
- le raisonnement scientifique ;
- la connaissance du terrain ;
- la réflexion méthodologique.
Elles servent surtout :
à quantifier l’incertitude
pour raisonner rigoureusement
à partir de données imparfaites.
Ce que les grands jeux de données changent
Avec beaucoup de données :
- presque tout peut devenir significatif ;
- les faux positifs augmentent ;
- la validation externe devient essentielle ;
- les tailles d’effet deviennent indispensables.
Ce que les données dépendantes changent
Lorsque les observations se ressemblent :
- les tests classiques deviennent trop optimistes ;
- les IC deviennent trop étroits ;
- les conclusions peuvent devenir trompeuses.
Plus de données ne signifie pas toujours :
plus d’information.
Ce qu’il faut retenir
Avant d’interpréter une relation :
- observer les données ;
- quantifier l’incertitude ;
- discuter les hypothèses ;
- replacer les résultats dans leur contexte ;
- rester prudent dans les conclusions.
Une relation statistique
n’est jamais une interprétation automatique.
Transition vers la séance 3
Dans la prochaine séance :
nous travaillerons sur des variables quantitatives.
Nous verrons notamment :
- covariance et corrélation ;
- corrélation de Pearson ;
- corrélation de Spearman ;
- comparaison de moyennes ;
- relations entre variables quantitatives.
Une continuité importante
Même si les méthodes changent : les questions restent les mêmes.
Toujours se demander :
- que mesure-t-on ?
- que compare-t-on ?
- quelle est l’incertitude ?
- quelles hypothèses fait-on ?
- que peut-on réellement conclure ?
Exos ?
![]()
Comment interpréter un IC à 95 % ?
Un intervalle de confiance à 95 % signifie que :
En pratique : - intervalle étroit → estimation plus précise ; - intervalle large → incertitude plus importante.