# A tibble: 3 × 88
id EA_HAB EA_LIT EA_MAL EA_JOUE EA_AID EA_EMM EA_SATTACHE OA_VAISS OA_REPAS
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 NA NA NA NA NA NA NA NA NA
2 2 NA NA NA NA NA NA NA NA NA
3 3 NA NA NA NA NA NA NA NA NA
# ℹ 78 more variables: OA_ALIME <dbl>, OA_LINGE <dbl>, OA_ASPIR <dbl>,
# OA_BRICO <dbl>, OA_COMPT <dbl>, OA_INVIT <dbl>, OA_SATREP <dbl>,
# OB_DACHQUO <dbl>, OB_DACHEX <dbl>, OB_DEDUC <dbl>, OB_DLOISIR <dbl>,
# OB_GESTION <dbl>, OC_SATREL <dbl>, OC_DESTAC <dbl>, VA_MARIDEP <dbl>,
# VA_COHAB <dbl>, VA_MARITJS <dbl>, VA_DIVORC <dbl>, VA_FEMENF <dbl>,
# VA_HOMENF <dbl>, VA_DEUXPAR <dbl>, VA_MERSEUL <dbl>, VA_EFTAUTO <dbl>,
# VA_DROITHOMO <dbl>, VA_GPOCCPE <dbl>, VA_PARAIDENF <dbl>, …Initiation à l’analyse statistique
ED de l’Université de Bordeaux
2026
Séance 1 : Se familiariser avec ses données et poser des bases solides
Claire Kersuzan
PUD-Bx / Progedo · LifeObs / Ined · COMPTRASEC / UB
Karine Onfroy
Bordeaux School Economics (BxSE) / UB
1. INTRODUCTION
Qui sommes-nous ?
Claire Kersuzan
- Docteure en démographie, ingénieure de recherche (PUD-Bx / Progedo, LifeObs / INED, Comptrasec/UB)
- Statistique publique, réutilisation des données
- Formation et accompagnement (Data-SHS, école d’été, etc.)
Karine Onfroy
- Ingénieure d’études en soutien à la recherche (Bordeaux School of Economics / UB)
- Collecte, traitement et analyse de données d’enquête
- Mise en place de la plateforme expérimentale BILBO (Behavioural Insights Laboratory - Bordeaux)
Deux approches des données
Claire
Grandes enquêtes (stat. publique)
- enquêtes de grande taille
- données standardisées
- pondérations, nomenclatures
- réutilisation et valorisation de données existantes
Karine
Données de recherche
- données produites pour une question scientifique
- protocoles plus flexibles
- terrains et méthodes variés
- collecte et traitement des données
Deux approches différentes… mais les mêmes enjeux : comprendre, vérifier et interpréter les données rigoureusement.
Et vous ?
En quelques données (33s)
- Prénom ;
- Discipline(s) ;
- Sujet de thèse ;
- Type de données utilisées ? (ou envisagées)
- Plus gros casse-tête avec les données ?
- Une chose que vous aimeriez apprendre ?
- Session du cours qui vous intéresse le plus (1, 2, 3,4, toutes, ne sais pas)
Des données très différentes
Dans cette formation, vous travaillez donc sur :
- des objets de recherche variés ;
- des méthodes différentes ;
- des données très diverses.
Mais une question commune :
comment analyser ces données de manière rigoureuse ?
Plan de la séance
1. Pourquoi ?
- raisonnement
- question
- observation ≠ conclusion
2. Les données
- ERFI
- structure
- variables
3. Types de variables
- quali / quanti
- nominale / ordinale
- discrète / continue
4. Décrire
- tableaux / graphiques
- proportions
- moyenne, médiane
5. Vérifier
- manquants
- extrêmes
- incohérences
Objectif : raisonner sur les données avant les méthodes
2. A QUOI SERVENT LES STATISTIQUES ?
À quoi servent les statistiques ?
Quelle que soit la discipline, on cherche à répondre à des questions :
- existe-t-il des différences entre groupes ?
- un phénomène évolue-t-il dans le temps ?
- certains facteurs sont-ils associés ?
- observe-t-on un effet ?
Pour cela, il faut :
- Formuler et tester des hypothèses
- Organiser les données, vérifier leur qualité
- Produire des résultats interprétables, comprendre leurs limites
Statistiques = outil pour raisonner à partir de données.
3. UNE DEMARCHE
La démarche “QDAI”
Une analyse statistique suit souvent 4 étapes
QUESTION
→ ce que l’on cherche à comprendre
DONNÉES
→ ce que l’on observe
ANALYSE
→ ce que l’on fait avec les données
INTERPRÉTATION
→ ce que l’on conclut
Toujours dans cet ordre.
Application : Transformer une question générale en question statistique.
Exemple : “Les jeunes sont-ils plus favorables au divorce ?”
→ comment définir “jeunes” ?
→ comment mesurer cette opinion ?
→ quelles variables utiliser ?
→ qui comparer ?
Correction
Exemple de question statistique : “La proportion d’individus favorables au divorce diffère-t-elle selon l’âge ?”
Exemple de questions d’une enquête (ERFI) :
Opinion sur le divorce
« Dans quelle mesure êtes-vous d’accord ou pas d’accord avec l’affirmation suivante ? » → « Si des gens sont malheureux en couple, ils peuvent divorcer, même s’ils ont des enfants. »**
Âge
→ « Quelle est votre date de naissance ? »
Questions méthodologiques importantes
- Comment définir “jeunes” ? → âge continu ? groupes d’âge ?
- Comment mesurer “être favorable” ? → modalités / score ?
- Observe-t-on un effet de l’âge… ou un effet de génération ?
→ Une question statistique nécessite toujours des choix de définition et de mesure.
On ne choisit pas une méthode au hasard
Avant toute analyse, il faut se demander :
- quelle est la question ?
- quelles données sont disponibles ?
- quelles variables utiliser ?
- que veut-on comparer ?
La méthode vient en dernier
La méthode découle toujours de la question et des données disponibles
On ne choisit pas une méthode au hasard
Erreurs fréquentes
- Commencer par une méthode (“Je vais faire un test…” sans savoir pourquoi)
- Analyser sans question claire (faire des calculs sans objectif )
- Interpréter sans comprendre les données (oublier comment elles ont été produites)
- Confondre résultat et conclusion (confondre différence observée et effet réel)
Les statistiques ne sont pas des recettes mais une manière de raisonner
4. OBSERVER NE SUFFIT PAS POUR CONCLURE
Observer une différence/tendance ne suffit pas pour conclure
- une différence observée ≠ un effet réel
→ les groupes étaient-ils comparables au départ ? - une corrélation ≠ une causalité
→ deux phénomènes peuvent varier de la même façon sans lien direct
- un résultat statistique ≠ une conclusion scientifique
→ est-il important ? robuste ? généralisable ?
Pourquoi ?
→ hasard ; biais ; groupes non comparables ; facteurs non observés.
Les statistiques servent aussi à évaluer l’incertitude.
Corrélation trompeuse
Deux variables peuvent évoluer ensemble… sans avoir de lien réel.

Exemple :
- volume de recherches Google pour “How much wood can a woodchuck chuck”
- et consommation de kérosène au Venezuela.

Une explication… convaincante ?
Une “histoire” générée par IA
> Les marmottes, réalisant l’inutilité de leurs efforts à lancer du bois, se seraient tournées vers d’autres activités, entraînant indirectement une hausse de la consommation de kérosène…
→ Cette explication est absurde… mais elle donne une impression de cohérence
Pourquoi ?
- L’IA, comme notre cerveau, cherche du sens
- Elle relie des éléments même sans lien réel
- Elle construit une histoire plausible à partir d’une corrélation
Corrélation ≠ causalité
Votre avis
Comment expliquer cette relation ?
- hasard ?
- facteur caché ?
- tendance commune dans le temps ?
- problème de mesure ?
- simple coïncidence ?
Une corrélation observée ne signifie pas forcément qu’il existe un lien causal.
Plus on dispose de données, plus on peut trouver de corrélations… même absurdes.
Autres exemples :
https://www.tylervigen.com/spuriouscorrelations
Observation vs expérimental
Observationnel
- on observe sans intervenir ;
- groupes souvent différents au départ ;
- facteurs non observés possibles.
on identifie surtout des associations
Expérimental
- on intervient sur la situation ;
- conditions plus contrôlées ;
- groupes rendus comparables.
on peut davantage discuter d’un effet causal
5. DONNEES UTILISEES DURANT CE COURS
Les données utilisées durant ce cours
Nous travaillerons principalement sur :
ERFI (Étude des relations familiales et intergénérationnelles)
- grande enquête réalisée par l’Ined (dispositif GGS);
- environ 10 000 individus 18-79 ans interrogés ;
- famille, couple, relations sociales ;
- questionnaire standardisé.
Un jeu de données réel (mais anonymisé), riche… et imparfait.
Des thématiques qui parlent à tout le monde
→ Apprendre des réflexes transférables
Première observation
À votre avis :
quelles difficultés peut-on rencontrer dans une enquête de ce type ?
quelles limites peut-on déjà imaginer ?
quelles informations peuvent manquer ?
Ce que l’on peut déjà anticiper
Dans une enquête comme ERFI, on peut rencontrer :
- des non-réponses ;
- des erreurs ou imprécisions ;
- des variables difficiles à interpréter ;
- des informations manquantes ;
- des biais liés à la collecte.
Certaines situations peuvent aussi être difficiles à mesurer : → opinions ; relations familiales ; souvenirs ou déclarations.
Les données ne sont jamais “parfaites” : elles sont produites dans un contexte précis.
6. COMPRENDRES SES DONNEES
Comprendre ses données
Avant d’analyser, il faut comprendre :
- d’où viennent les données ;
- comment elles ont été produites ;
- ce qu’elles représentent réellement ;
- quelles sont leurs limites.
Les données ne sont pas la réalité,
mais une représentation du réel.
Exemple : les données ERFI
Les données sont issues :
- d’un questionnaire rempli par des individus ;
- dans un contexte précis.
Cela implique :
- réponses déclaratives ;
- filtres dans les questions ;
- non-réponses ;
- catégories construites.
Les données dépendent toujours
de la manière dont elles ont été produites.
Application
Prenons une variable du questionnaire ERFI : VA_DIFFAGE
Dans quelle mesure êtes-vous d’accord ou pas d’accord avec cette propositions ? “Dans un couple, c’est mieux quand l’homme est plus âgé que la femme.”
→ Modalités : D’accord, Plutôt d’accord, Ni d’accord, ni pas d’accord, Plutôt pas d’accord, Pas d’accord, Ne sait pas
À votre avis :
- que mesure réellement cette variable ?
- mesure-t-elle une pratique ou une opinion ?
- que signifie “être d’accord” avec cette phrase ?
- quelles limites voyez-vous dans cette formulation ?
Correction
VA_DIFFAGE > “Dans un couple, c’est mieux quand l’homme est plus âgé que la femme.”
Points importants
- opinion déclarée à propos norme conjugale, pas une pratique ;
- “être d’accord” = possibles interprétations différentes ;
- formulation oriente vers norme de couple hétérosexuel ;
- réponses transformées en catégories codées ;
- modalité “ne sait pas” doit être repérée et interprétée.
Une variable ne mesure jamais directement “la réalité” : elle mesure une réponse à une question formulée dans un cadre précis.
Une variable n’est jamais neutre
Une variable correspond toujours à :
- une question ;
- une formulation ;
- un codage ;
- des catégories de réponse ;
- des choix méthodologiques.
Exemple : VA_DIFFAGE
→ opinion recueillie à partir d’une phrase proposée aux enquêté·es
→ réponses en 5 modalités (D’accord à Pas d’accord) transformées en codes numériques.
Pourquoi un dictionnaire des variables ?
Le dictionnaire permet de comprendre :
- ce que mesure une variable ;
- à quoi correspondent les codes ;
- qui est concerné par la question ;
- quelles valeurs sont particulières.
Exemple : VA_DIFFAGE
→ Modalités :1 = D’accord, 2 = Plutôt d’accord, 3 = Ni d’accord ni pas d’accord,4 = Plutôt pas d’accord,5 = Pas d’accord, 9 = Ne sait pas
Sans dictionnaire, un code numérique peut être mal interprété.
Réflexe essentiel
Avant d’analyser, toujours se demander :
- que mesure réellement cette variable ?
- comment a-t-elle été construite ?
- que ne mesure-t-elle pas ?
Les données ont un contexte
Un tableau seul ne suffit pas.
Pour comprendre les données, il faut :
- le questionnaire
- le dictionnaire des variables
- le contexte de collecte
Sans contexte, les résultats peuvent être trompeurs
A retenir
Comprendre les données fait partie du travail statistique.
C’est une étape indispensable
Avant de faire des tests ou des modèles : comprendre les variables, le contexte et les limites des données.
Une mauvaise compréhension
= de mauvaises conclusions
7. STRUCTURE DES DONNEES
Structure des données
On ne fait pas des statistiques sur des idées, mais sur des jeux de données.
Un jeu de données
Dans la plupart des cas :
- les lignes = des observations ;
- les colonnes = des variables.
| id | âge | diplôme | opinion divorce |
|---|---|---|---|
| 1 | 25 | Bac+3 | D’accord |
| 2 | 54 | CAP | Pas d’accord |
Une ligne correspond à une unité d’observation.
Question
Dans ERFI :
que représente une ligne ?
- une personne ?
- un couple ?
- un ménage ?
- une réponse ?
Correction
Dans ERFI :
une ligne = un individu interrogé
Chaque ligne correspond donc : à une personne avec ses caractéristiques, ses réponses et ses opinions.
Mais ce n’est pas toujours le cas dans d’autres données
Une ligne peut aussi représenter :
- un ménage ;
- une région ;
- une année ;
- une consultation médicale ;
- une expérience ;
- etc.
Le niveau d’analyse change
les analyses possibles et leur interprétation.
Pourquoi est-ce important ?
Selon ce que représente une ligne :
- on ne fait pas les mêmes analyses ;
- on ne compte pas les mêmes choses ;
- on n’interprète pas les résultats de la même manière.
Exemple :
→ compter des individus ≠ compter des événements ≠ compter des ménages ≠ compter des observations répétées.
Toujours savoir ce qu’une ligne représente.
Relier des données
Parfois, les informations sont réparties dans plusieurs fichiers.
On peut alors les relier grâce à :
- un identifiant ;
- une jointure.
Exemple
- un fichier “individus” ;
- un fichier “ménages” ;
- un fichier “revenus”.
Il faut vérifier après la jointure :
- pertes de lignes ;
- doublons ;
- valeurs manquantes ;
- erreurs de correspondance.
Réflexe essentiel
Avant d’analyser :
- que représente une ligne ?
- à quel niveau travaille-t-on ?
- les données ont-elles été transformées ?
- plusieurs fichiers ont-ils été fusionnés ?
Comprendre la structure des données fait partie de l’analyse.
8. Types de variables
Types de variables
Toutes les variables ne se manipulent pas de la même façon.
Le type de variable influence :
- les graphiques ;
- les indicateurs ;
- les analyses possibles.
Deux grandes familles de variables
Variables qualitatives
→ catégories
Exemples :
- sexe ;
- diplôme ;
- opinion.
Variables quantitatives
→ valeurs numériques
Exemples :
- âge ;
- revenu ;
- nombre d’enfants.
Quelques précisions
Variables qualitatives
nominales → pas d’ordre
ordinales → ordre entre catégories
Variables quantitatives
discrètes → valeurs comptées
continues → valeurs mesurées
Piège classique
Un nombre n’est pas forcément une quantité.
Exemple :
- code postal ;
- numéro étudiant ;
- identifiant.
Ces variables sont numériques… mais pas quantitatives.
→ On ne peut pas calculer une moyenne sur un numéro de téléphone.
Activité
À votre avis, quel est le type de ces variables ?
| Variable | Type ? |
|---|---|
MA_SEXE |
? |
MC_DIPLOME |
? |
NBENFTOTM_rec |
? |
MA_AGEM_rec |
? |
VA_DIVORC |
? |
VA_DIFFAGE |
? |
Correction
| Variable | Type |
|---|---|
MA_SEXE |
qualitative nominale |
MC_DIPLOME |
qualitative ordinale |
NBENFTOTM_rec |
quantitative discrète |
MA_AGEM_rec |
quantitative continue |
VA_DIVORC |
qualitative ordinale |
VA_DIFFAGE |
qualitative ordinale |
Cas particulier : le temps
Certaines données évoluent dans le temps :
- dates ;
- durées ;
- suivis d’individus.
Dans ce cas :
- les observations peuvent être liées ;
- les méthodes deviennent plus spécifiques.
Nous ne traiterons pas ces méthodes ici.
Réflexe essentiel
Avant d’analyser une variable :
- que représente-t-elle réellement ?
- quelles sont ses modalités ?
- existe-t-il un ordre ?
- s’agit-il d’une mesure ou d’une catégorie ?
Ce n’est pas la forme de la variable qui compte,
mais son sens.
9. DECRIRE (qualitatif)
Pourquoi décrire ?
Avant toute analyse :
on commence toujours par décrire les données.
Pourquoi ?
- comprendre la population étudiée ;
- repérer des déséquilibres ;
- détecter des problèmes ;
- éviter des contresens.
On ne peut pas interpréter
ce qu’on n’a pas d’abord décrit.
Décrire une variable qualitative
Variable qualitative = catégories.
Exemples dans ERFI :
MA_SEXEMC_DIPLOMEVA_DIVORC
Pour la décrire, on regarde :
- les effectifs → combien ?
- les proportions → quelle part ?
Problème
Les effectifs dépendent de la taille de l’échantillon
Difficile de comparer
Passer aux proportions
Les proportions permettent de comparer
Interpréter une distribution
Questions à se poser :
- quelle catégorie est la plus fréquente ?
- certaines catégories sont-elles rares ?
- la distribution est-elle équilibrée ?
- observe-t-on des regroupements ?
Exemple :
- certaines catégories de diplôme sont très représentées (CAP/BEP) ;
- d’autres beaucoup moins (diplômes supérieurs).
Décrire, ce n’est pas seulement lire des chiffres : c’est comprendre la structure des données et caractéristiques de l’échantillon
Visualiser les catégories
Un graphique permet souvent de voir plus rapidement :
- les catégories dominantes ;
- les déséquilibres ;
- les écarts importants.
Exemple de diagramme en barres
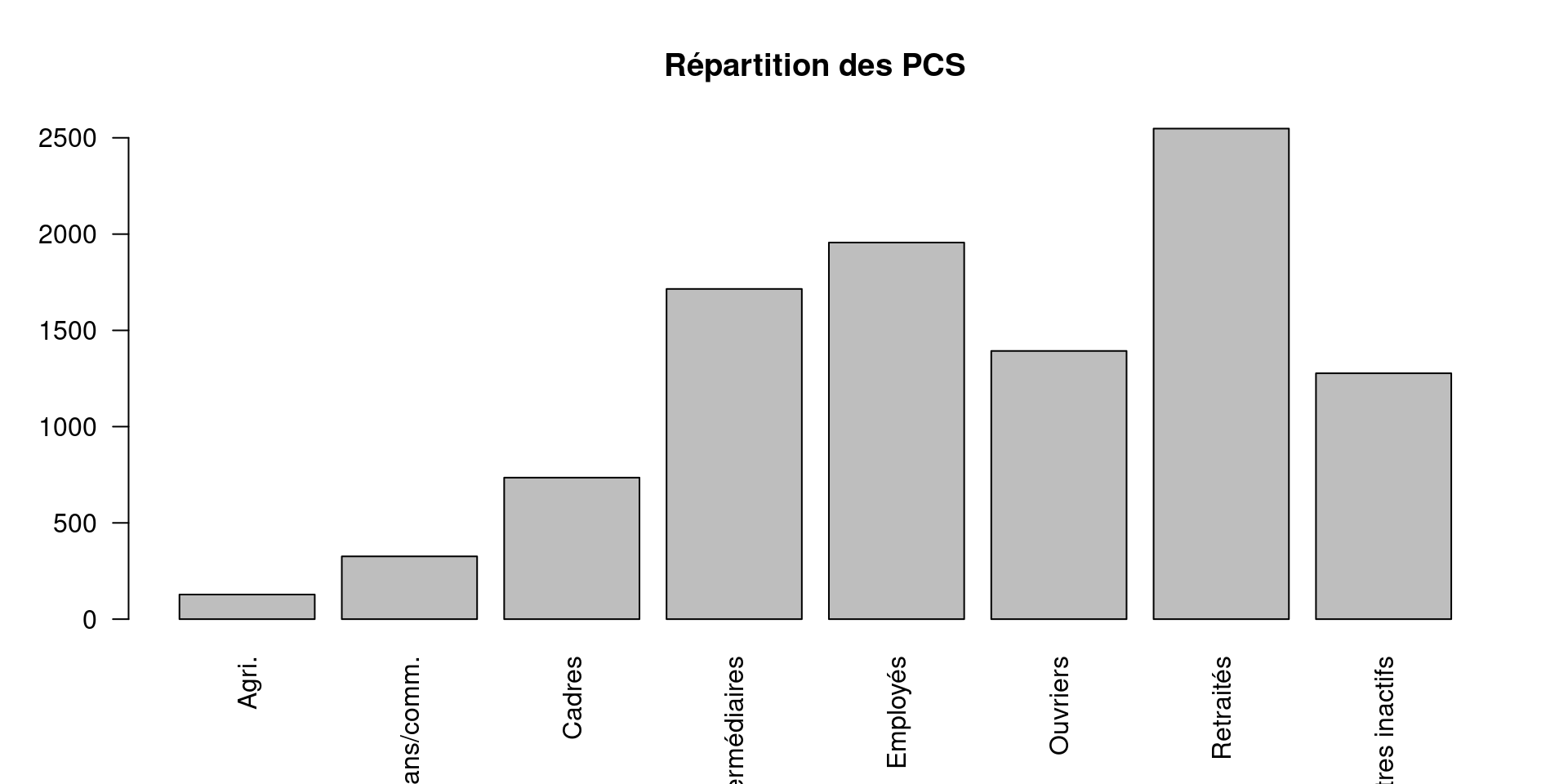
que représentent les barres ?
quelles catégories dominent ?
certaines catégories sont-elles peu représentées ?
le graphique semble-t-il équilibré ?
Lire un diagramme en barres
- hauteur des barres → effectifs ou %
- comparaison visuelle entre catégories
Intérêt :
- repérer rapidement les catégories dominantes
- identifier des déséquilibres
Point clé
Un graphique n’est pas une décoration. C’est un outil :
- d’exploration ;
- de comparaison ;
- d’interprétation.
Un bon graphique doit être :
- lisible ;
- simple (Trop d’information = moins de compréhension) ;
- interprétable en quelques secondes.
Règles simples
Un graphique doit comporter :
- un titre explicite
- des axes nommés (avec les unités)
- une légende claire
- une source (si nécessaire)
Couleurs et esthétique
- utiliser peu de couleurs
- rester cohérent
- éviter le décoratif
- privilégier des palettes inclusives (ex :
RColorBrewer)
L’esthétique sert la compréhension
A retenir
Décrire une variable qualitative, c’est :
- mesurer des proportions
- comparer des catégories
- visualiser pour mieux comprendre
10. DECRIRE (quantitatif)
Décrire une variable quantitative
Exemples dans ERFI :
MA_AGEM_rec→ âge ;NBENFTOTM_rec→ nombre d’enfants.
> Ce sont des valeurs numériques.
Question
Comment résumer une variable quantitative ?
Exemple :
- les âges ;
- les revenus ;
- les durées ;
- les nombres d’enfants.
Première étape : regarder
Avant de calculer : observer la distribution.
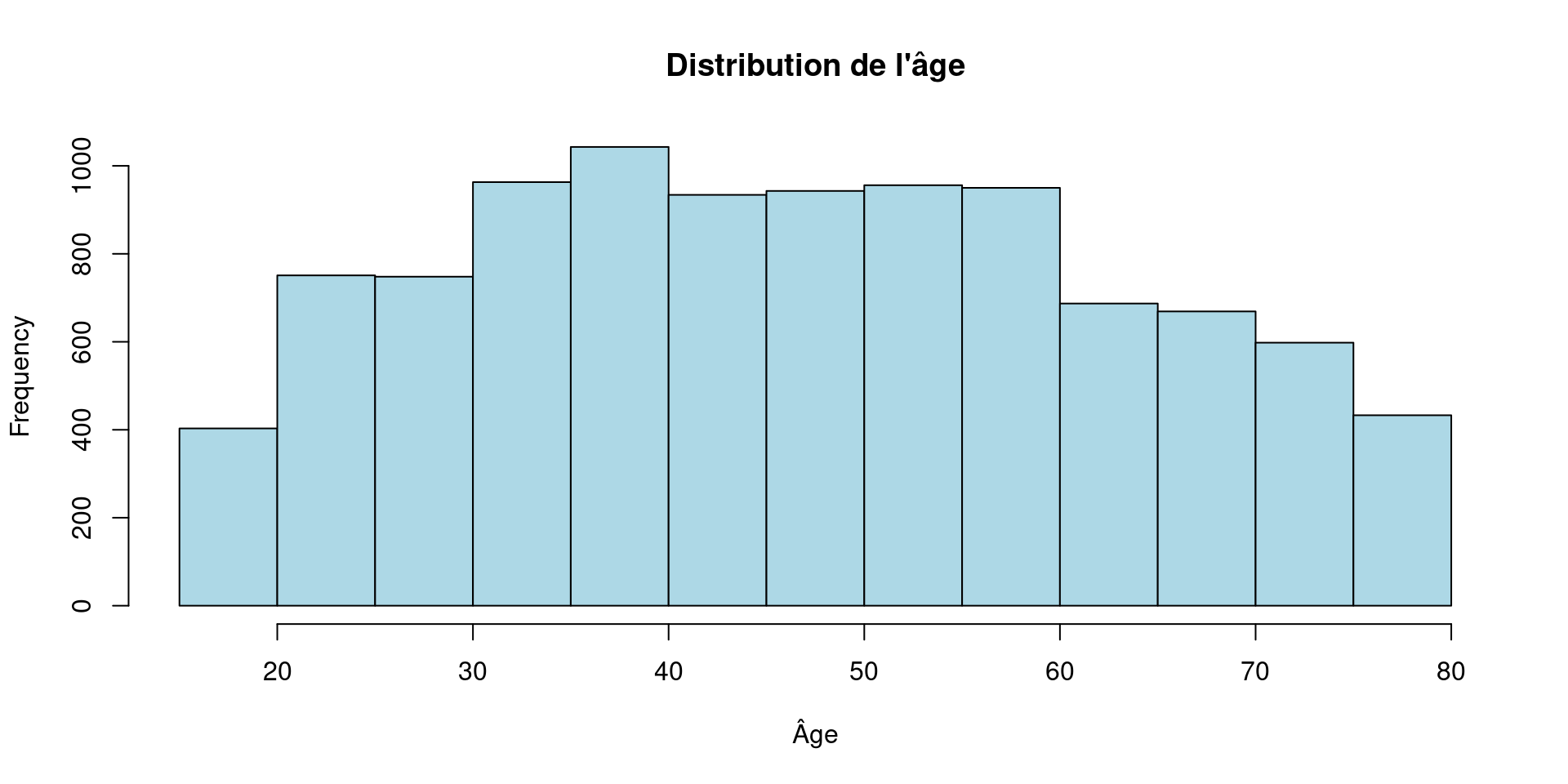
Que peut-on observer ?
- les âges sont-ils répartis uniformément ?
- certaines valeurs sont-elles particulières ?
- la distribution semble-t-elle symétrique ?
Un histogramme
Permet de voir :
- la forme de la distribution
- la dispersion
- les valeurs extrêmes
première lecture des données
Ensuite : résumer
On cherche souvent à résumer :
- le centre ;
- la dispersion ;
- l’étendue des valeurs.
11. Résumer le centre d’une distribution
Résumer le centre d’une distribution
Pour résumer le “centre” d’une distribution, on utilise souvent :
- la moyenne ;
- la médiane.
Mais ces deux indicateurs ne racontent pas toujours la même histoire.
La moyenne
Somme des valeurs divisée par le nombre d’observations
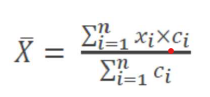
Exemple
D’autres types de moyennes
La moyenne “classique” est la moyenne arithmétique.
Mais d’autres types de moyennes existent, > selon la nature des données et la question posée.
| Type de moyenne | Principe | Utilisation fréquente |
|---|---|---|
| Moyenne arithmétique | somme des valeurs / nombre d’observations | variables quantitatives classiques |
| Moyenne géométrique | racine du produit des valeurs | taux de croissance, données multiplicatives |
| Moyenne harmonique | inverse de la moyenne des inverses | vitesses, ratios, fréquences |
La médiane
valeur qui partage la population en deux
Exemple
→ 50 % des individus ont un âge inférieur
→ 50 % ont un âge supérieur
Application
5 revenus mensuels (€) :
1180 – 1480 – 1590 – 2130 – 9350
À votre avis :
- la moyenne sera-t-elle proche de la médiane ?
- pourquoi ?
Correction
5 revenus (€) :
1180 – 1480 – 1590 – 2130 – 9350
→ moyenne = 3146 €
→ médiane = 1590 €
Une seule valeur élevée modifie fortement la moyenne
Comprendre la différence
- moyenne → sensible aux valeurs extrêmes
- médiane → plus robuste
Les deux ne racontent pas toujours la même histoire
Choisir un indicateur
Données équilibrées (sans valeurs extrêmes)
→ moyenne et médiane proches
→ la moyenne résume bien l’ensemble des données
Données asymétriques
→ moyenne ≠ médiane
→ la médiane décrit mieux la situation
Discussion
On interroge 5 diplômés d’un doctorat
et on observe leurs revenus mensuels 1 an après leur thèse (€) :
1180 – 1480 – 1590 – 2130 – 9350
- moyenne = 3146 €
- médiane = 1590 €
Question
- Quel indicateur donne une image “optimiste” de l’insertion des diplômés ?
- Lequel est le plus représentatif de la situation de la majorité des individus ?
Discussion (2)
L’indicateur retenu change l’interprétation
Le choix dépend aussi de la question posée
A retenir
Un indicateur statistique :
- simplifie les données ;
- mais ne représente jamais parfaitement la réalité.
Résumer des données,
c’est déjà faire des choix d’interprétation.
12. VARIABILITE
Question
Deux situations peuvent-elles avoir la même moyenne
mais être différentes ?
Exemple
Deux groupes :
- âge moyen = 47 ans
Mais :
- groupe 1 : entre 45 et 50 ans
- groupe 2 : de 20 à 75 ans
Ces deux groupes ont-ils vraiment le même profil ?
Le centre insuffisant pour la description
Décrire une distribution, ce n’est pas seulement décrire son centre.
Il faut aussi comprendre :
- si les valeurs sont proches ;
- ou très dispersées.
C’est ce qu’on appelle la variabilité
Pourquoi la variabilité est-elle importante ?
Elle permet de :
- comprendre l’hétérogénéité ;
- comparer des situations ;
- éviter des interprétations trompeuses.
Deux moyennes identiques peuvent correspondre à des réalités très différentes.
Une première manière de mesurer la variabilité
Découper la population en 4 groupes de même taille :
- 25 % des individus (Q1)
- 50 % (médiane)
- 75 % (Q3)
Ce sont les quartiles
Exemple (Age dans ERFI)
Interpréter les quartiles
Dans ERFI :
- 25 % des individus ont moins de 34 ans
- 50 % ont moins de 47 ans
- 75 % ont moins de 60 ans
Donc :
50 % des individus ont entre 34 (Q1) et 60 ans (Q3)
→ intervalle assez large (les âges sont assez dispersés)
13. VISUALISER
Visualiser la variabilité : le boxplot
Le boxplot (ou boîte à moustaches) résume graphiquement une distribution
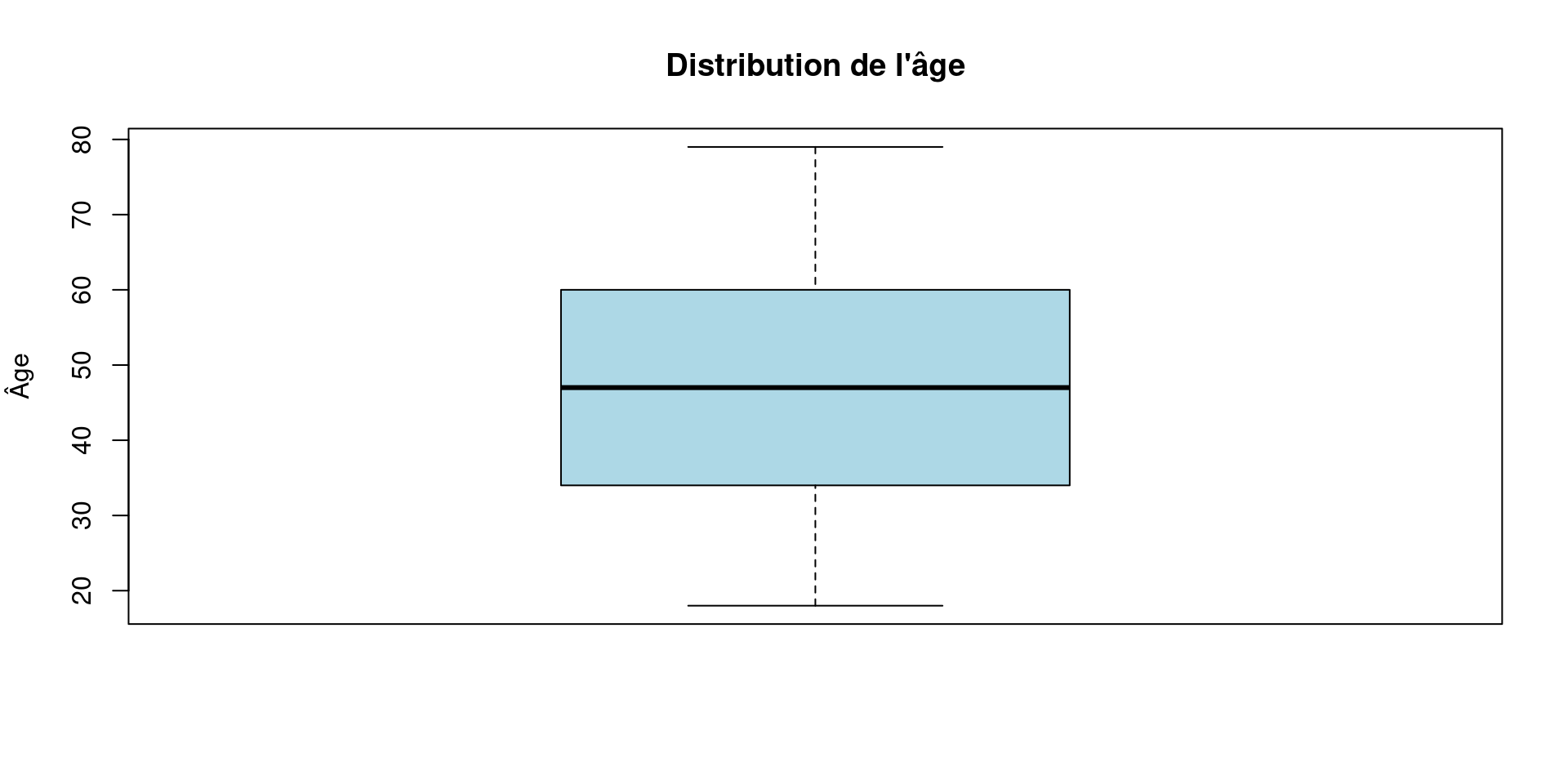
Lire un boxplot
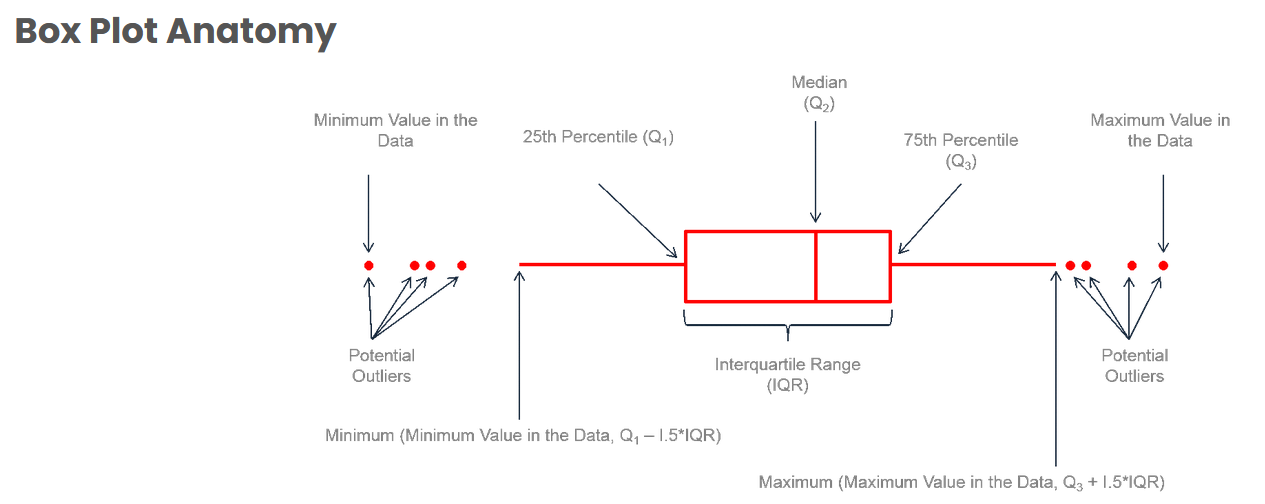
Un boxplot représente :
- la médiane
- les quartiles et l’étendue
- les valeurs extrêmes
La variabilité n’est pas un “problème”, c’est une information essentielle
→ c’est elle qui rend les données intéressantes
Valeurs extrêmes
Certaines valeurs attirent l’attention :
- très élevées ;
- très faibles ;
- très éloignées du reste des données.
Mais sont-elles forcément “anormales” ?
Discussion
Une valeur très élevée peut correspondre :
- à une erreur ?
- à un cas rare mais réel ?
- à un codage particulier ?
- à une situation exceptionnelle ?
Comment le savoir ?
Repérer des valeurs atypiques
Le boxplot permet de repérer :
→ des valeurs éloignées du reste des données
- points isolés
- en dehors de l’intervalle habituel
Ces valeurs sont définies par une règle statistique :
- en dessous de Q1 − 1,5 × IQR
- au-dessus de Q3 + 1,5 × IQR
Mais ce n’est qu’une convention
Point clé
Une valeur extrême n’est pas forcément une erreur
Elle peut être :
- réelle (cas rare)
- une erreur de saisie
- une valeur particulière (codage)
Toujours interpréter avant de supprimer ou corriger
Variabilité et valeurs extrêmes
Les valeurs extrêmes font partie
de la variabilité des données.
Mais elles peuvent fortement influencer :
- la moyenne ;
- certains graphiques ;
- certains indicateurs statistiques.
Une autre manière de mesurer la variabilité
L’écart-type

Lire l’écart-type
À quelle distance, en moyenne, les valeurs sont-elles de la moyenne ?
Intuition
- faible → valeurs proches
- élevé → valeurs dispersées
→ mesure globale de la dispersion
Exemple
Limite
L’écart-type est influencé par les valeurs extrêmes
comme la moyenne
Ecart_type VS Quartiles
- écart-type → basé sur la moyenne, sensible aux valeurs extrêmes
- quartiles → basés sur la distribution
Les quartiles sont plus robustes aux valeurs extrêmes
Point clé
Il n’existe pas une seule manière
de décrire la variabilité
Chaque outil donne une information différente
Synthèse
Pour comprendre une variable quantitative, on combine :
- histogramme → forme
- moyenne / médiane → position
- quartiles / boxplot → structure
- écart-type → dispersion
Aucun outil ne suffit seul
C’est leur combinaison qui permet une bonne compréhension
Décrire… c’est déjà vérifier
Décrire les données, ce n’est pas seulement résumer
En explorant :
- tableaux
- graphiques
- indicateurs
On commence à repérer des situations “problématiques”
Dans ERFI, par exemple :
- valeurs manquantes (NA)
- valeurs très élevées (ex : temps de trajet)
- modalités peu fréquentes
- codes particuliers (ex : 97 = “non concerné”)
Décrire les données, c’est déjà commencer à les questionner
14. VERIFIER SES DONNEES
Vérifier ses données
Avant d’aller plus loin :
il faut vérifier ce que contiennent réellement les données
Les données ne sont jamais parfaites.
- incomplètes
- mal codées
- ou difficiles à interpréter
Une grande partie du travail statistique consiste à comprendre et préparer les données
Types de situations fréquentes
Dans un jeu de données comme ERFI, on peut rencontrer :
- des valeurs manquantes
- des valeurs extrêmes
- des incohérences
- des codes spécifiques
- des modalités rares
Chaque cas demande une interprétation (et un traitement spécifique)
Toujours se demander : qu’est ce que cela signifie? Est-ce une erreur? Une modalité prévue par l’enquête? Une situation particulière? Une information utile?
15. VALEURS MANQUANTES
Valeurs manquantes
Certaines informations ne sont pas renseignées
Exemple :
Min. 1st Qu. Median Mean 3rd Qu. Max. NAs
1.00 2.00 3.00 28.03 97.00 97.00 7687 Beaucoup de valeurs manquantes
Question
Peut-on simplement les ignorer ?
Première étape : comprendre
Toutes les valeurs manquantes ne sont pas des erreurs
Dans une enquête :
- non-réponse
- question non posée (filtre)
- information inconnue
Exemple :
- questions sur la répartition des tâches d’éducation des enfants dans le couple
→ uniquement si la personne est en couple et a des jeunes enfants
→ sinon : valeur manquante
Une valeur manquante peut donc être… normale
Point clé
Une valeur manquante = une information sur les données
Pas seulement “un trou”
Pourquoi c’est important ?
Les valeurs manquantes peuvent :
- réduire le nombre d’observations
- modifier les comparaisons
- introduire des biais
On n’analyse plus forcément la même population.
Exemple
Si les valeurs manquantes concernent surtout :
- les personnes les plus jeunes ;
- les personnes les moins diplômées ;
- les personnes sans enfant ;
- les personnes ayant une situation précaire.
que peut-il se passer dans l’analyse ?
Trois situations possibles
Les valeurs manquantes peuvent être :
- sans lien avec les données
- liées à certaines variables observées
- liées à ce que l’on cherche à mesurer (cas le plus problématique)
Plus les données manquantes sont liées au phénomène étudié, plus l’analyse peut être biaisée
Conséquence
On ne peut pas traiter toutes les valeurs manquantes de la même façon
Donc, avant toute décision
Toujours se demander :
- combien y en a-t-il ?
- pourquoi sont-elles absentes ?
- qui est concerné ?
- sont-elles liées à la question étudiée ?
Pourquoi c’est crucial ?
Si certains groupes répondent moins :
- ils sont moins présents dans l’analyse
- les résultats peuvent être biaisés
On n’analyse plus vraiment la même population
Conséquence
Supprimer des données peut modifier la structure de l’échantillon
→ et donc les résultats
Que peut-on faire ?
Selon les cas, on peut :
- supprimer les observations concernées
- créer une modalité à part (qualitatif)
- remplacer par une valeur centrale (quantitatif)
- imputer une valeur probable
Attention
Chaque choix peut modifier :
- les distributions
- les comparaisons
- les conclusions
Traiter les valeurs manquantes,
c’est faire des choix qui influencent l’analyse
Conclusion
Le traitement des valeurs manquantes fait partie intégrante de l’analyse.
Ce n’est pas une étape technique
C’est une étape de raisonnement
16. VALEURS EXTREMES … OU ABERRANTES ?
Valeurs extrêmes… ou aberrantes ?
Dans les graphiques (histogramme, boxplot),
on observe parfois des valeurs très élevées ou très faibles.
Par exemple dans ERFI :
Min. 1st Qu. Median Mean 3rd Qu. Max. NAs
0.000 8.000 9.000 8.531 10.000 98.000 5304 maximum = 98
Est-ce réaliste… ou problématique ?
Point clé
Une valeur extrême est une alerte
qui demande à être vérifiée et interprétée

Interpréter une valeur extrême
Une valeur très élevée peut être :
réaliste → situation rare mais possible
une erreur → problème de saisie
une valeur “technique”
→ ex : “ne sait pas”, “non concerné” codé numériquement
Une valeur extrême doit toujours être interprétée
Repérer les valeurs extrêmes
Le boxplot permet de les identifier : points isolés (valeurs éloignées du reste)
Règle utilisée
- valeurs < Q1 − 1,5 × IQR
- valeurs > Q3 + 1,5 × IQR
Convention statistique, pas une définition absolue
Important
Une valeur “atypique” n’est pas forcément une erreur
Autres approches possibles :
- seuils statistiques (écart-type)
- seuils métier (ex : âge > 130 ans)
- connaissance du terrain
Et concrètement ?
Le graphique (boxplot) permet de repérer
mais c’est à nous de décider
Que faire ?
Une valeur extrême doit être :
- vérifiée
- comprise et justifiée
Puis, plusieurs options :
- conserver la valeur
- corriger une erreur de saisie
- exclure une observation
- transformer (logarithme, racine carrée, etc.)
- winsoriser (remplacer par un seuil)
Le choix dépend du contexte et des objectif de l’analyse
Pourquoi c’est important ?
Les valeurs extrêmes peuvent :
- modifier fortement la moyenne
- influencer une corrélation
- “tirer” une régression
- perturber certains tests statistiques
Méthodes sensibles :
- moyenne / écart-type
- corrélation de Pearson
- régression linéaire
- t-test, ANOVA
Une seule valeur peut parfois changer les résultats
Important
Supprimer une valeur extrême n’est jamais automatique.
Une suppression doit être :
- argumentée
- documentée
- reproductible
On doit pouvoir expliquer pourquoi une observation a été retirée.
17. NETTOYER C’EST ANALYSER
Autres types de problèmes
Les valeurs extrêmes ne sont pas les seuls cas.
On peut aussi rencontrer :
- incohérences
- doublons
Incohérences
Certaines informations ne sont pas compatibles entre elles
Exemple :
- individu sans enfant
- mais réponse à une question sur les devoirs
Quelle information est correcte ?
→ Nécessite une interprétation
Doublons
Une même unité apparaît plusieurs fois
Dans ERFI :
- chaque ligne = un individu
Donc :
un identifiant (
id) doit être unique
- Si
TRUE: erreur… ou cas particulier ?
Un doublon dépend de la structure des données
Doublon et structure des données
Cas 1 — Données individuelles
- une ligne = un individu > doublon = problème probable
Cas 2 : données temporelles*
- une ligne = un individu à un moment donné > plusieurs lignes (normal = suivi dans le temps
| id | année | revenu |
|---|---|---|
| 1 | 2020 | 1500 |
| 1 | 2021 | 1600 |
Identifier une observation
Parfois une seule variable (id) ne suffit pas
Il faut combiner :
- individu + année
- individu + événement
- ménage + individu
On parle d’identifiant composite
Autres cas possibles
données par événement
une ligne = un événement (ex : consultation, achat)
données hiérarchiques
plusieurs lignes liées à une même unité
(ex : plusieurs enfants pour un même parent)
Donc, avant de conclure
Toujours se demander :
- qu’est-ce qu’une ligne représente ?
- quelles variables définissent une observation unique ?
En résumé
- valeur extrême → à interpréter
- incohérence → à vérifier
- doublon → dépend du contexte
Modalités rares
Certaines catégories ont très peu d’effectifs
Exemple :
Certaines modalités sont peu représentées
Pourquoi c’est un problème ?
- comparaisons difficiles
- résultats instables
- forte sensibilité aux variations
Une proportion sur 3 individus n’a pas le même sens que sur 300
Et pour la suite…
Certaines méthodes statistiques nécessitent des effectifs suffisants (ex : test du khi², etc.)
Si ce n’est pas le cas :
- résultats peu fiables, voires invalides
- interprétation délicate
Que faire concrètement ?
Il n’existe pas une seule solution
Selon le cas, on peut :
- conserver (si plausible)
- corriger (si erreur identifiable)
- exclure (si donnée inutilisable)
- regrouper (si catégories trop rares)
Exemple ERFI
regrouper des modalités rares
→ ex : rapprocher certaines catégories de fréquence de visiteexclure des valeurs incohérentes
→ ex : notes de satisfaction aberrantestraiter les valeurs manquantes
→ ex : imputation
Attention
Regrouper des catégories…
c’est modifier la variable
→ donc modifier les résultats, et les interprétations
Vérifier la robustesse
Quand plusieurs choix sont possibles :
- comparer les résultats
- tester plusieurs traitements
Exemples :
- avec / sans valeurs extrêmes
- différents traitements des valeurs manquantes
- différents regroupements de modalités
Interprétation
- résultats proches → conclusions plus robustes
- résultats différents → prudence
Les résultats dépendent des choix faits en amont
Autres possibilités
- S’appuyer sur la littérature scientifique de votre domaine
- Et les pratiques majoritaires dans votre discipline
En pratique…
Analyser des données, ce n’est pas seulement
appliquer des méthodes
C’est aussi :
- comprendre les données
- faire des choix, les justifier et les documenter
- accepter une part d’incertitude
Conclusion
Il n’y a pas toujours une “bonne” réponse
Mais il y a des choix :
- plus cohérents
- plus justifiés
- plus transparents
Et c’est cela, faire une bonne analyse = être capable de justifier et d’expliquer les choix méthodologiques tout au long du processus, et d’évaluer leurs conséquences sur les résultats
Ce que permet la statistique descriptive
La statistique descriptive permet de :
- comprendre la population étudiée
- résumer les distributions
- repérer des problèmes dans les données
- traiter certaines situations
→ valeurs manquantes, incohérences, valeurs extrêmes
- préparer les analyses suivantes
Décrire, ce n’est pas seulement produire des chiffres
c’est comprendre ce que l’on observe
Point clé
La statistique descriptive est une étape
essentielle et indispensable avant toute analyse
Sans elle :
- mauvaise compréhension des données
- méthodes inadaptées
- interprétations erronées
Mais aussi…
La statistique descriptive intervient à plusieurs moments :
- avant → comprendre et préparer les données
- pendant → guider les choix
- après → interpréter les résultats
Elle permet de donner du sens aux résultats
Mais décrire ne suffit pas
Les statistiques descriptives permettent d’observer…
Mais elles ne permettent pas de conclure que :
- une différence est significative
- une relation est explicative
- une relation est causale
- un résultat est généralisable
Décrire ≠ conclure
Une idée centrale : l’incertitude
Ce que l’on observe peut varier :
- selon les individus
- selon les données disponibles
- selon les choix de traitement
- selon le hasard
Toute analyse comporte une part de variabilité donc une part d’incertitude
Une grande partie des méthodes statistiques = mesurer cette incertitude
Aller plus loin : croiser les variables
Jusqu’ici, on a décrit des variables une par une.
Mais une question de recherche porte souvent sur une relation :
La répartition des tâches domestiques
varie-t-elle selon l’âge ? la PCS ?, etc.
Dans les prochaines séances
Séance 2 Explorer les relations entre variables qualitatives
→ tableaux croisés, proportions conditionnelles, test du khi², interprétation des résultats
Séance 3 Explorer les variables quantitatives
→ distributions, corrélations, t-test et comparaison de moyennes, valeurs extrêmes
Nous passerons progressivement de la description
à l’analyse des relations entre variables
Pour conclure
Aujourd’hui, nous avons posé les bases :
- formuler une question
- comprendre les données
- identifier les variables
- décrire avant d’expliquer
- vérifier la qualité des données
Prendre le temps de comprendre ce qu’on manipule avant d’appliquer des méthodes
Prochaine étape : apprendre à distinguer ce que l’on observe de ce que l’on peut conclure
Ce qu’il faut retenir
Une analyse statistique ne commence pas par un test.
Elle commence par des questions simples :
- qu’est-ce qu’une ligne ?
- que mesure chaque variable ?
- qui est concerné par la question ?
- quelles valeurs sont manquantes ?
- quelles valeurs sont atypiques ?
- quels choix de traitement peuvent changer les résultats ?
Les calculs viennent après, le raisonnement vient avant.
18. MISE EN PRATIQUE AVEC ERFI
Mise en pratique avec ERFI
Vous allez maintenant jouer le rôle d’analystes de données.
Votre mission
- télécharger le projet (.zip) depuis le site du cours
(Menu « Exercices » → « Séance 1 »)
https://vf-ed-stat-2026-00446e.gitpages.huma-num.fr/
- ouvrir les données dans R / RStudio ;
- consulter le dictionnaire des codes et le questionnaire ;
- réaliser la fiche d’exercice ;
- proposer et justifier vos choix de traitement.
L’objectif n’est pas de trouver “la bonne réponse”,
mais d’apprendre à raisonner sur les données.
Ressources à utiliser
Dans le fichier .zip, vous trouverez :
- le projet R de l’exercice (à ouvrir)
- le fichier de données (.csv) dans le dossier *data*
- le dictionnaire des codes dans le dossier *metadonnees*
- le questionnaire ERFI dans le dossier *metadonnees*
- la fiche d’exercice (Exo_Seance1.qmd)
Pensez à vous appuyer sur les métadonnées :
elles sont indispensables pour interpréter correctement les variables.
Packages R utiles pour explorer un jeu de données
Explorer rapidement un dataset
- skimr → moyenne, médiane, écart-type, quantiles, histogrammes et statistiques adaptées au type de variable
- summarytools→ résumés descriptifs complets et tableaux HTML lisibles
- DataExplorer → vue d’ensemble rapide d’un dataset (types de variables, distributions, valeurs manquantes, corrélations…)
- psych → descriptives complètes (skewness, kurtosis, min/max, etc.)
Produire de beaux tableaux descriptifs
- gtsummary → tableaux descriptifs lisibles et facilement exportables
- sjPlot → produire rapidement des tableaux et visualiser les distributions
Packages R utiles pour vérifier qualité des données
Explorer les valeurs manquantes
naniar→ cartographier les NA et explorer les patterns de non-réponseVIM→ explorer et visualiser les données manquantes
Détecter des valeurs atypiques
rstatix→ identifier des valeurs atypiquesperformance→ vérifier certains diagnostics de modèles statistiques
![]()
Comment formuler une question statistique ?
Passer d’une question générale à une question que l’on peut analyser statistiquement.
Exemples :
Question générale : “Les relations parents-enfants changent-elles avec l’âge ?”
→ Question statistique : “La fréquence des contacts avec les parents diffère-t-elle selon l’âge des individus ?”
Question générale → “Réviser permet-il de réussir un examen ?”
→ Question statistique → “La proportion d’étudiants ayant réussi est-elle plus élevée chez ceux ayant révisé ?”