if (!require("pacman")) install.packages("pacman")
pacman::p_load(dplyr, ggplot2, gtsummary, here)
library(tidyverse)
library(dplyr)Séance 1 — Se familiariser avec ses données et poser des bases solides
(à compléter par vos soins durant séance)
1 EXERCICE 1 Correction
Obj. : Comprendre et traiter une variable quantitative imparfaite (vie réelle)
On s’intéresse à la variable suivante :
PA_DURMTRA: durée du trajet domicile–domicile de la mère (en minutes)
L’objectif n’est pas seulement de décrire cette variable, mais de réfléchir à :
- ce que représentent réellement les données ;
- l’origine des valeurs manquantes ;
- la présence de valeurs extrêmes ;
- l’impact des choix de traitement sur les résultats.
1.1 1. Ouvrir le dictionnaire des variables, le questionnaire et notez vos remarques ci-dessous
1.2 2. Charger les packages
On commence par charger les packages utiles.
1.3 3. Ouvrir les données
On ouvre ensuite le fichier de données.
TipVoir le code
ERFI <- read_csv("../data/ERFI1_FPA.csv")1.4 4. Explorer la variable
Commencez par observer la distribution de la variable PA_DURMTRA (summary, histogramme, boxplot).
TipVoir le code
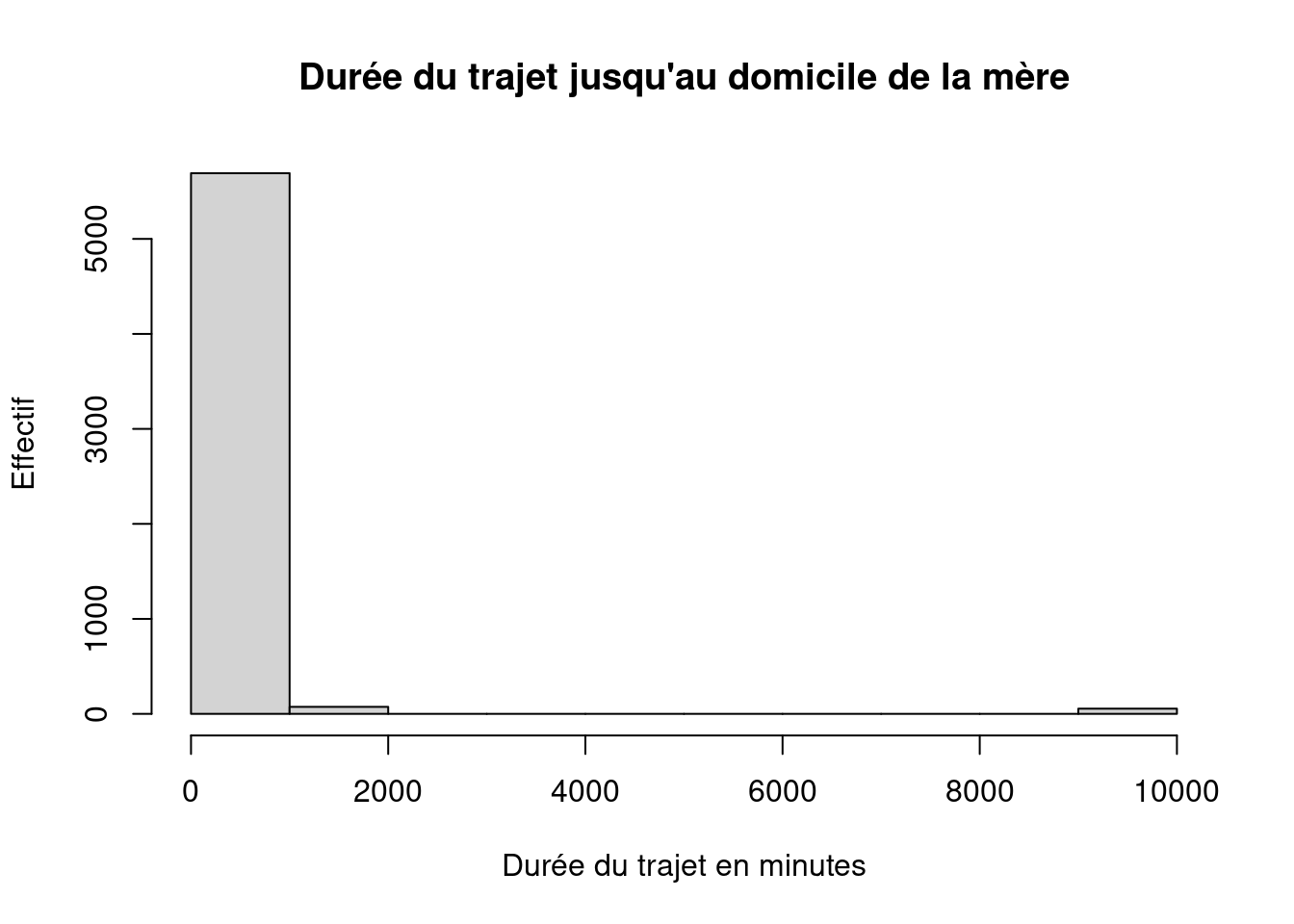
summary(ERFI$PA_DURMTRA) Min. 1st Qu. Median Mean 3rd Qu. Max. NAs
0.0 10.0 30.0 221.9 150.0 9999.0 4258 mean(ERFI$PA_DURMTRA, na.rm = TRUE)[1] 221.9021median(ERFI$PA_DURMTRA, na.rm = TRUE)[1] 30hist(
ERFI$PA_DURMTRA,
main = "Durée du trajet jusqu'au domicile de la mère",
xlab = "Durée du trajet en minutes",
ylab = "Effectif"
)
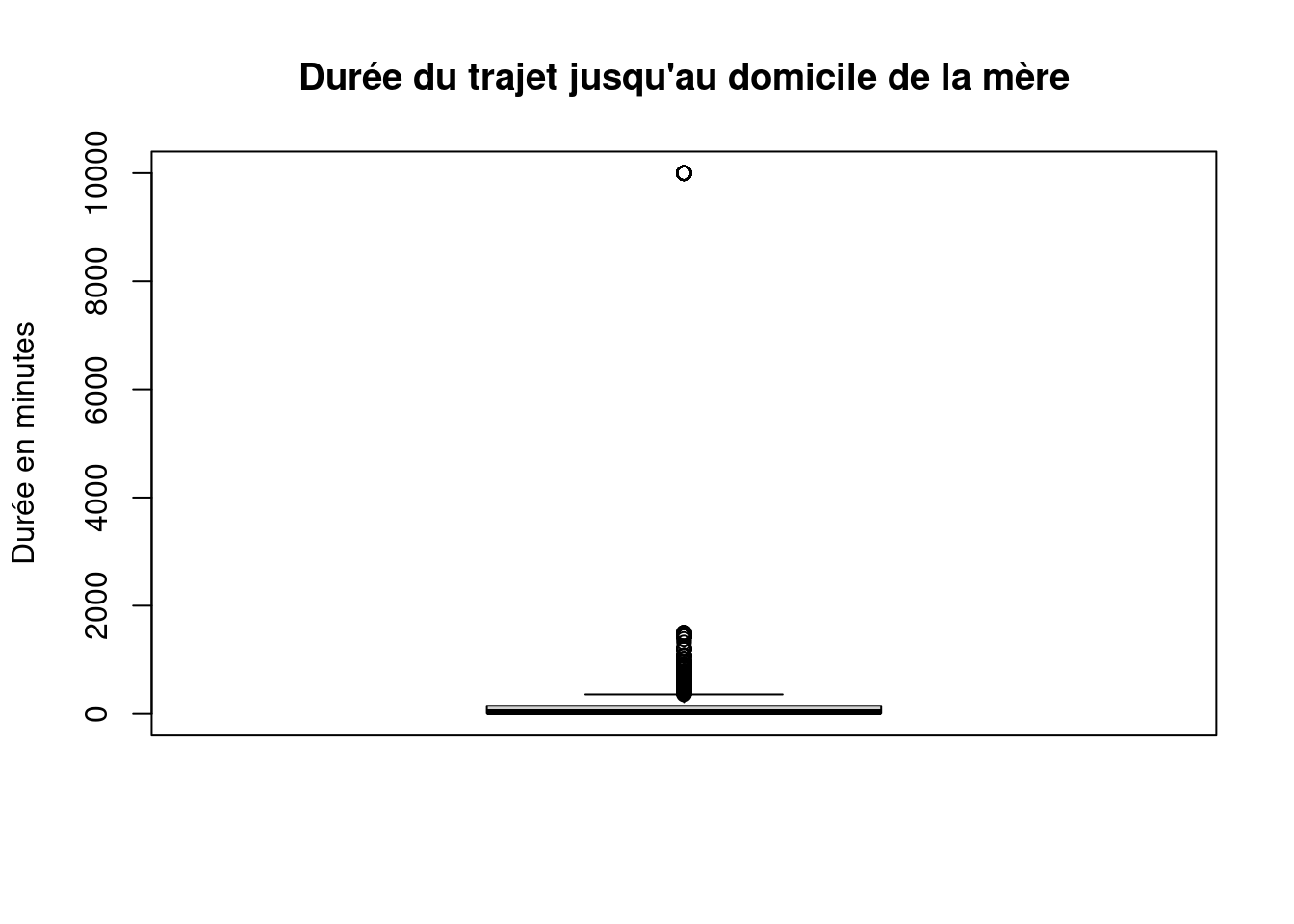
boxplot(
as.numeric(ERFI$PA_DURMTRA),
main = "Durée du trajet jusqu'au domicile de la mère",
ylab = "Durée en minutes"
)
1.5 5. Questions de base
Pourquoi utiliser les fonctions summary, hist et boxplot ?
Que remarquez-vous concernant :
- la médiane ?
- la moyenne ?
- les valeurs extrêmes ?
- la médiane ?
La distribution vous semble-t-elle symétrique ?
Quelle différence observez-vous entre moyenne et médiane ?
Que cela suggère-t-il sur la distribution ?
NoteVoir les réponses
On observe une forte différence entre la moyenne et la médiane.
- médiane ≈ 30 minutes
- moyenne ≈ 222 minutes
- maximum = 9999 minutes
La distribution est donc très asymétrique (étirée vers les grandes valeurs).
- La médiane décrit le “cas typique”
- La moyenne est tirée vers le haut par quelques valeurs extrêmes
Cela suggère une distribution très dispersée avec des valeurs atypiques importantes.
1.6 6. Les valeurs manquantes
On observe un grand nombre de valeurs manquantes.
1.6.1 Questions
Pourquoi cette variable n’est-elle pas renseignée pour tous les individus ?
Qui est concerné par cette question ?
NoteVoir les réponses
Un grand nombre de valeurs manquantes est observé.
Ce n’est pas forcément un problème de données.
Cette variable n’est renseignée que pour les individus concernés :
- si la mère est en vie
- si la distance est connue
Donc :
- NA ≠ erreur
- NA = information sur la population
1.7 7. Les valeurs problématiques
Certaines valeurs peuvent sembler très élevées (par exemple 9999).
1.7.1 Questions
Une durée de 9999 minutes est-elle réaliste ?
Convertissez en heures puis en jours.Que peut représenter cette valeur dans un questionnaire ?
Faut-il la considérer comme :
- une valeur réelle ?
- un code particulier ?
TipVoir le code
max(ERFI$PA_DURMTRA, na.rm = TRUE)[1] 99999999 / 60[1] 166.659999 / 60 / 24[1] 6.94375
NoteVoir les réponses
9999 minutes ≈ 167 heures ≈ presque 7 jours.
Ce n’est pas une durée réaliste.
Cette valeur correspond très probablement à un code particulier :
- non réponse
- valeur inconnue
- valeur technique
Elle ne doit pas être traitée comme une vraie donnée.
1.7.2 Les corriger
On décide de traiter la valeur 9999 comme une valeur non valide. Construire la base trajet en éliminant cette valeur de l’analyse et regardez de nouveau la distribution de la variable PA_DURMTRA (summary, histogramme, boxplot)
TipVoir le code
trajet <- ERFI$PA_DURMTRA
trajet[trajet == 9999] <- NA
summary(trajet) Min. 1st Qu. Median Mean 3rd Qu. Max. NAs
0.0 10.0 30.0 128.6 150.0 1499.0 4313 mean(trajet, na.rm = TRUE)[1] 128.6415median(trajet, na.rm = TRUE)[1] 30min(trajet, na.rm = TRUE)[1] 0max(trajet, na.rm = TRUE)[1] 14991.7.3 Et alors ?
- Que devient la moyenne après correction ?
- La médiane change-t-elle ?
- Pourquoi ?
NoteVoir les réponses
Après correction :
- moyenne ≈ 129 minutes
- médiane = 30 minutes (inchangée)
La moyenne chute fortement
La médiane reste stable
Conclusion :
- la moyenne est très sensible aux valeurs extrêmes
- la médiane est robuste
Une seule valeur aberrante peut modifier fortement la moyenne.
1.8 8. Les valeurs aberrantes
Après avoir transformé la valeur problématique en NA, on observe encore des valeurs très élevées (jusqu’à 1499 minutes).
1.8.1 Questions
Une durée de 1499 minutes vous semble-t-elle plausible ?
Dans quels cas pourrait-elle l’être ?À partir de quelle valeur considéreriez-vous une durée comme “aberrante” ?
Sur quoi repose votre choix :
- une règle statistique ?
- une connaissance du terrain ?
- un choix arbitraire
NoteVoir les réponses
Même après correction, on observe des valeurs très élevées (jusqu’à 1499 minutes ≈ 25h).
Ces valeurs sont extrêmes mais pas forcément fausses.
Elles peuvent correspondre à :
- une grande distance géographique
- un déplacement exceptionnel
À partir de quand une valeur devient-elle “aberrante” ?
Cela dépend :
- du contexte
- de la question de recherche
- du jugement du chercheur
Il n’existe pas de règle universelle.
1.8.2 Comparer plusieurs méthodes de traitement
On propose trois approches :
- Conserver toutes les valeurs
- Supprimer les valeurs extrêmes (par exemple > 600 minutes)
- Tronquer (caper) les valeurs extrêmes (remplacer les valeurs > 600 par 600)
TipVoir le code
trajet_valide <- trajet[!is.na(trajet)]
mean(trajet_valide)[1] 128.6415median(trajet_valide)[1] 30trajet_filtre <- trajet_valide[trajet_valide <= 600]
mean(trajet_filtre)[1] 97.27909median(trajet_filtre)[1] 30trajet_cap <- trajet_valide
trajet_cap[trajet_cap > 600] <- 600
mean(trajet_cap)[1] 115.1524median(trajet_cap)[1] 301.8.3 Et alors ?
NoteVoir les réponses
Comparaison :
- données complètes → moyenne ≈ 129
- suppression (>600) → moyenne ≈ 97
- capping → moyenne ≈ 115
La médiane reste toujours ≈ 30
Interprétation :
- la médiane est stable
- la moyenne dépend fortement des valeurs extrêmes
Le choix du traitement change le résultat.
Donc :
Il n’existe pas UNE moyenne, mais plusieurs moyennes selon les choix faits.
1.8.4 Discuter le choix du seuil (600 minutes)
Dans cet exercice, un seuil de 600 minutes (10 heures) est utilisé.
Pourquoi ce seuil a-t-il été choisi selon vous ?
Ce choix vous semble-t-il :
- justifié ?
- arbitraire ?
Quels autres seuils aurait on pu utilisés ?
Quelles informations supplémentaires seraient nécessaires pour faire un choix plus rigoureux ?
NoteVoir les réponses
Le seuil de 600 minutes (10 heures) a été choisi ici comme exemple de valeur très élevée.
Ce choix peut sembler raisonnable car :
- il permet d’identifier des durées très inhabituelles ;
- il limite l’influence des valeurs extrêmes sur la moyenne ;
- il conserve malgré tout des trajets longs plausibles.
Mais ce seuil reste largement arbitraire.
Pourquoi 600 plutôt que :
- 300 minutes ?
- 480 minutes ?
- 1000 minutes ?
Il n’existe pas de seuil “naturel”.
Un choix plus rigoureux pourrait s’appuyer sur :
- la connaissance du terrain ;
- la distribution observée ;
- des critères statistiques ;
- ou encore des informations complémentaires sur les individus (lieu de résidence et pays de résidence de la mère, cohérence avec d’autres variables, etc.).
Cela rappelle qu’en statistique appliquée :
traiter les valeurs extrêmes n’est pas seulement une question technique, mais aussi une question d’interprétation et de connaissance des données.
1.9 9. Conséquences pour l’analyse statistique
1.9.1 Questions
Quel est l’impact des valeurs extrêmes sur :
- la moyenne ?
- la variance ?
Si vous utilisiez cette variable dans une analyse statistique (corrélation, régression, test), que se passerait-il si vous conserviez ces valeurs extrêmes ?
Quels risques cela pose-t-il pour l’inférence statistique ?
NoteVoir les réponses
Les valeurs extrêmes ont plusieurs effets :
- elles augmentent la moyenne
- elles gonflent la variance
- elles influencent fortement les résultats
En inférence :
- elles peuvent fausser une corrélation
- elles peuvent modifier les coefficients d’une régression
- elles peuvent rendre les tests instables
Quelques observations peuvent suffire à changer les conclusions.
Garder ces valeurs sans réflexion peut ainsi conduire à des résultats trompeurs.
1.10 CONCLUSION Q1
Peut-on dire qu’il existe une seule “bonne” manière de traiter ces données ?
De quoi dépend le choix de la méthode ?
Que retenez-vous de cet exercice sur le lien entre :
- données ;
- choix méthodologiques ;
- résultats statistiques ?
NoteVoir les réponses
Il n’existe pas de “bonne” méthode unique.
Le choix dépend :
- de la question de recherche
- du sens des données
- du contexte
- des hypothèses
Les résultats statistiques dépendent des choix méthodologiques.
En conclusion :
- les données doivent être comprises avant d’être analysées
- les traitements influencent les résultats
- une analyse doit toujours être justifiée et transparente
2 EXERCICE 2 Correction
Explorer avant d’interpréter
Obj. : Comprendre les données avant de les analyser Explorer avant d’interpréter
La question de départ est :
Les tâches domestiques sont-elles partagées dans le couple ?
2.1 1. Prendre en main les données
2.1.1 Charger les packages utiles
On commence par charger les packages utiles.
library(tidyverse)
library(dplyr)2.1.2 Ouvrir les données
On ouvre ensuite le fichier de données.
TipVoir le code
ERFI <- read_csv("../data/ERFI1_FPA.csv")On observe rapidement la structure générale du fichier.
TipVoir le code
dim(ERFI)[1] 10079 86head(ERFI)# A tibble: 6 × 86
id EA_HAB EA_LIT EA_MAL EA_JOUE EA_AID EA_EMM EA_SATTACHE OA_VAISS OA_REPAS
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 NA NA NA NA NA NA NA NA NA
2 2 NA NA NA NA NA NA NA NA NA
3 3 NA NA NA NA NA NA NA NA NA
4 4 8 8 4 3 2 7 8 5 5
5 5 NA NA NA NA NA NA NA NA NA
6 6 NA NA NA NA NA NA NA 3 4
# ℹ 76 more variables: OA_ALIME <dbl>, OA_LINGE <dbl>, OA_ASPIR <dbl>,
# OA_BRICO <dbl>, OA_COMPT <dbl>, OA_INVIT <dbl>, OA_SATREP <dbl>,
# OB_DACHQUO <dbl>, OB_DACHEX <dbl>, OB_DEDUC <dbl>, OB_DLOISIR <dbl>,
# OB_GESTION <dbl>, OC_SATREL <dbl>, OC_DESTAC <dbl>, VA_MARIDEP <dbl>,
# VA_COHAB <dbl>, VA_MARITJS <dbl>, VA_DIVORC <dbl>, VA_FEMENF <dbl>,
# VA_HOMENF <dbl>, VA_DEUXPAR <dbl>, VA_MERSEUL <dbl>, VA_EFTAUTO <dbl>,
# VA_DROITHOMO <dbl>, VA_GPOCCPE <dbl>, VA_PARAIDENF <dbl>, …2.1.3 Questions de base
- Combien y a-t-il d’individus dans le fichier ?
- Combien y a-t-il de variables ?
- Que représente une ligne dans ce tableau ?
- Que représente une colonne ?
NoteVoir les réponses
Le fichier contient 10 079 individus et 86 variables.
Une ligne correspond à un individu enquêté.
Une colonne correspond à une variable, c’est-à-dire une information collectée sur les individus : sexe, type de ménage, présence d’un conjoint, répartition des tâches domestiques, etc.
NoteAvant toute analyse
De quoi sont faites mes données ?
- Qui est observé ?
- À quel niveau ?
- Dans quel contexte ?
Une même table peut correspondre à des réalités très différentes
2.2 2. Sélectionner les variables utiles
2.2.1 Construire une base de travail
Pour cet exercice, on ne va pas utiliser toutes les variables du fichier.
On crée l’objet ERFI_sel en sélectionnant uniquement les variables nécessaires pour étudier la répartition des tâches domestiques dans le couple.
On ajoutera à cet ensemble : - le sexe
- la variable indiquant la présence d’un conjoint dans le ménage
- le type de ménage
- l’âge.
NoteVoir les variables utilisées
Les variables utilisées sont :
MA_SEXE: sexe du répondant
EA_VERIFC: présence d’un conjoint
TYPFAM3_rec: type de ménageMA_AGEM_rec: l’âge des enquêté.es
OA_REPAS: préparation des repas
OA_VAISS: vaisselle
OA_LINGE: linge
OA_COMPT: comptes
OA_BRICO: bricolage
OA_ASPIR: aspirateur
OA_ALIME: courses d’alimentation
TipVoir le code
ERFI_sel <- ERFI |>
select(
MA_SEXE,
EA_VERIFC,
TYPFAM3_rec,
MA_AGEM_rec,
OA_REPAS,
OA_VAISS,
OA_LINGE,
OA_COMPT,
OA_BRICO,
OA_ASPIR,
OA_ALIME
)2.2.2 Vérifier le résultat
head(ERFI_sel)# A tibble: 6 × 11
MA_SEXE EA_VERIFC TYPFAM3_rec MA_AGEM_rec OA_REPAS OA_VAISS OA_LINGE OA_COMPT
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 2 1 48 NA NA NA NA
2 2 2 1 34 NA NA NA NA
3 2 2 1 19 NA NA NA NA
4 1 1 4 36 5 5 5 3
5 1 2 1 31 NA NA NA NA
6 1 1 3 48 4 3 3 1
# ℹ 3 more variables: OA_BRICO <dbl>, OA_ASPIR <dbl>, OA_ALIME <dbl>2.2.3 Questions
Combien de variables conserve-t-on ?
Quelles variables décrivent les caractéristiques des individus ?
Quelles variables décrivent l’organisation des tâches domestiques ?
NoteVoir les réponses
On conserve 11 variables.
Les variables qui décrivent les caractéristiques des individus ou du ménage sont :
MA_SEXEEA_VERIFCTYPFAM3_recMA_AGEM_rec
Les variables qui décrivent l’organisation des tâches domestiques sont :
OA_REPASOA_VAISSOA_LINGEOA_COMPTOA_BRICOOA_ASPIROA_ALIME
:::
2.3 3. Comprendre la population étudiée
2.3.1 Décrire la population
Avant d’analyser les tâches domestiques, il est indispensable de comprendre qui est observé.
On commence donc par décrire la distribution de la population selon le type de ménage (TYPFAM3_rec), en effectifs puis en pourcentage.
TipVoir le code
# Effectifs
table(ERFI_sel$TYPFAM3_rec)
1 2 3 4 5
2642 670 2964 3124 679 # Pourcentages
prop.table(table(ERFI_sel$TYPFAM3_rec)) * 100
1 2 3 4 5
26.212918 6.647485 29.407679 30.995138 6.736779 2.3.2 Questions
- Quels types de ménages observe-t-on ?
- Quelle part vit en couple ?
- Toutes les personnes sont-elles concernées par les tâches domestiques ?
NoteVoir les réponses
On observe plusieurs types de ménages :
- personnes seules sans enfant (≈ 26 %)
- personnes seules avec enfant(s) (≈ 7 %)
- couples sans enfant (≈ 29 %)
- couples avec enfant(s) (≈ 31 %)
- autres configurations (ménages complexes), plus rares
Au total, environ 60 % des individus vivent en couple (modalités 3 et 4).
Cela signifie que près de 40 % des individus ne vivent pas en couple.
Or, la question posée porte sur le partage des tâches domestiques dans le couple.
Donc :
- une partie importante de la population n’est pas concernée par cette question ;
- leurs réponses (ou non-réponses) ne doivent pas être interprétées comme des comportements domestiques comparables.
Avant toute analyse, il faut toujours vérifier que la population étudiée correspond bien à la question posée.
2.3.3 Identifier la population concernée
Quelle variable permet de sélectionner la population concernée par les questions sur les tâches domestiques.
On regarde sa distribution.
NoteVoir la réponse
La variable EA_VERIFC indique si l’individu vit avec un conjoint dans le ménage.
Les modalités sont :
1: oui, présence d’un conjoint dans le ménage ;2: non, pas de conjoint dans le ménage.
On commence par regarder sa distribution, en effectifs puis en pourcentage
TipVoir le code
table(ERFI_sel$EA_VERIFC, useNA = "always")
1 2 <NA>
6088 3991 0 prop.table(table(ERFI_sel$EA_VERIFC)) * 100
1 2
60.40282 39.59718 2.3.4 Questions
- Combien d’individus vivent en couple ?
- Combien ne vivent pas en couple ?
- Pourquoi cette variable est-elle essentielle pour notre analyse?
NoteVoir les réponses
La variable EA_VERIFC montre que :
- 6 088 individus vivent avec un conjoint dans le ménage ;
- 3 991 individus ne vivent pas avec un conjoint.
Cela représente environ :
- 60,4 % des individus vivant avec un conjoint ;
- 39,6 % ne vivant pas avec un conjoint.
Cette variable est essentielle, car la question porte sur le partage des tâches dans le couple. Les personnes sans conjoint dans le ménage ne sont donc pas concernées de la même manière par cette analyse.
2.4 4. Commprendre les valeurs manquantes
2.4.1 Observer la variable OA_REPAS
On s’intéresse pour le moment à la variable OA_REPAS, qui porte sur la préparation des repas.
On regarde d’abord la distribution de la variable.
2.4.2 Croiser avec la présence d’un conjoint
Puis on croise la présence d’un conjoint avec le fait d’avoir ou non une réponse à OA_REPAS
TipVoir le code
# Distribution de la tâche "repas"
table(ERFI_sel$OA_REPAS, useNA = "always")
1 2 3 4 5 6 7 97 <NA>
1909 899 953 990 1309 13 12 3 3991 # Tableau croisé présence d'un conjoint * question sur les repas
table(
ERFI_sel$EA_VERIFC,
is.na(ERFI_sel$OA_REPAS)
)
FALSE TRUE
1 6088 0
2 0 39912.4.3 Questions
- Qui ne répond pas à la question ?
- Pourquoi ?
- Ces valeurs manquantes sont-elles des erreurs ?
NoteVoir les réponses
Les personnes qui ne répondent pas à la question OA_REPAS sont exactement celles qui ne vivent pas avec un conjoint dans le ménage.
Le tableau croisé montre que :
- les 6 088 personnes vivant avec un conjoint ont une réponse à
OA_REPAS; - les 3 991 personnes ne vivant pas avec un conjoint ont une valeur manquante.
Ces valeurs manquantes ne sont donc pas des erreurs.
Elles correspondent à un filtre du questionnaire : la question n’est pas posée aux personnes non concernées.
WarningAttention aux valeurs manquantes
Une valeur manquante peut être normale
- filtre du questionnaire
- question non posée
- individu non concerné
Il faut toujours comprendre leur origine
2.5 5. Restreindre l’analyse
2.5.1 Construire une base restreinte
Pour la suite, on travaille uniquement sur les individus vivant en couple.
On crée une nouvelle base ERFI_couple.
TipVoir le code
ERFI_couple <- ERFI_sel |>
filter(EA_VERIFC == 1)2.5.2 Vérifier le résultat
On vérifie la taille de la nouvelle base.
dim(ERFI_couple)[1] 6088 112.5.3 Questions
- Combien d’individus restent ?
- Qui a été exclu ?
- Pourquoi ce filtrage est-il nécessaire ?
NoteVoir les réponses
Après restriction aux individus vivant avec un conjoint, il reste 6 088 individus et 11 variables.
Les individus exclus sont ceux qui ne vivent pas avec un conjoint dans le ménage.
Ce filtrage est nécessaire car la question de recherche porte sur la répartition des tâches domestiques dans le couple.
Sans ce filtrage, on mélangerait des personnes concernées et non concernées par la question.
##6. Lire et interpréter une variable
2.5.4 Lire les modalités
Regardons de nouveau la distribution de la variable OA_REPAS.
table(ERFI_couple$OA_REPAS, useNA = "always")
1 2 3 4 5 6 7 97 <NA>
1909 899 953 990 1309 13 12 3 0 Quel libellé est associé à chacun des codes de la variable OA_REPAS ?
TipVoir les modalités
Les modalités sont :
1: toujours moi ;2: le plus souvent moi ;3: autant moi que mon conjoint ;4: le plus souvent mon conjoint ;5: toujours mon conjoint ;6: toujours ou le plus souvent d’autres membres du ménage ;7: toujours ou le plus souvent quelqu’un ne faisant pas partie du ménage ;97: n’est pas concerné.
2.5.5 Questions
- Quelle est la modalité la plus fréquente ?
- Que signifie “moi” ?
- Que représente la modalité
97?
- Peut-on conclure directement ?
- Est-il surprenant d’observer cette modalité même après avoir restreint l’analyse aux couples ?
NoteVoir les réponses
La modalité la plus fréquente de OA_REPAS est la modalité 1, c’est-à-dire “toujours moi”.
Mais on ne peut pas conclure directement que les repas sont majoritairement préparés par les femmes ou par les hommes.
La modalité “moi” dépend du sexe de la personne qui répond.
- Si la répondante est une femme, “moi” signifie une femme.
- Si le répondant est un homme, “moi” signifie un homme.
La modalité 97 signifie “n’est pas concerné”.
Il est un peu surprenant d’observer encore cette modalité après avoir restreint l’analyse aux couples, mais elle ne concerne que 3 individus. Cela peut correspondre à des situations particulières (repas externalisé, …) ou à des cas résiduels du questionnaire.
2.5.6 Visualiser une variable
Après avoir lu les effectifs dans un tableau, on peut représenter la distribution de OA_REPAS sous forme de graphique.
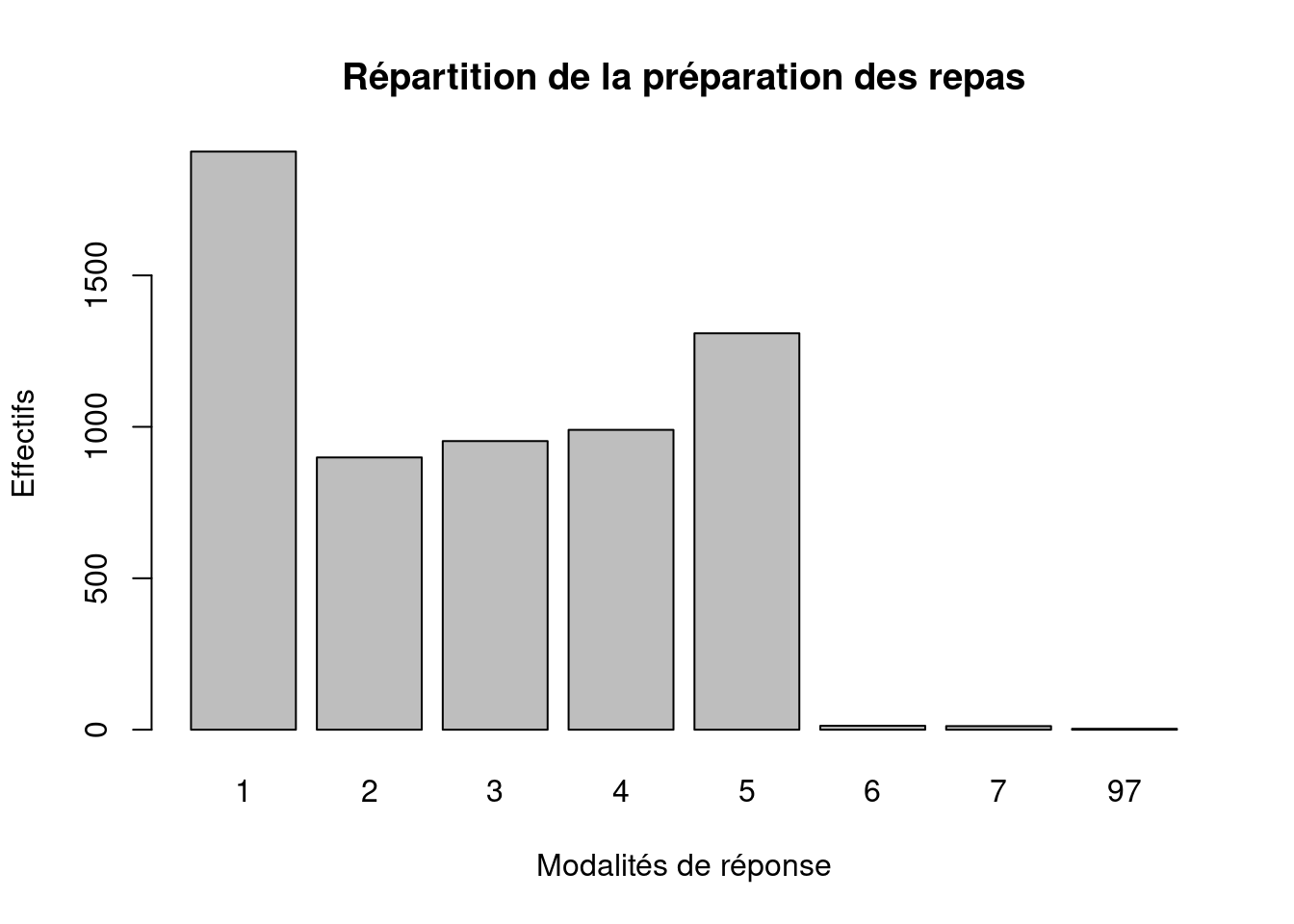
TipVoir le code
#Effectifs
barplot(
table(ERFI_couple$OA_REPAS),
main = "Répartition de la préparation des repas",
xlab = "Modalités de réponse",
ylab = "Effectifs"
)
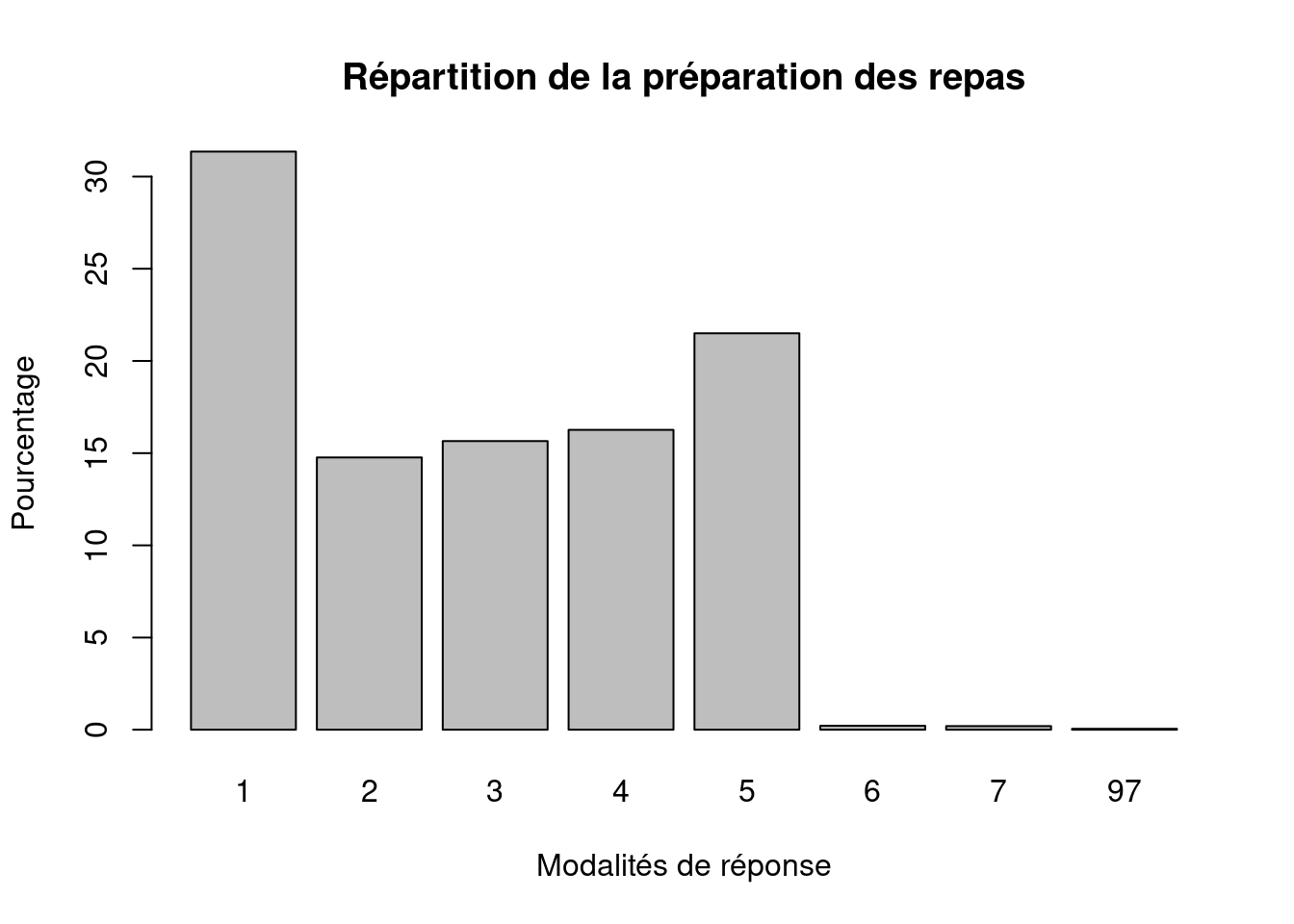
#Pourcentage
barplot(
prop.table(table(ERFI_couple$OA_REPAS)) * 100,
main = "Répartition de la préparation des repas",
xlab = "Modalités de réponse",
ylab = "Pourcentage"
)
2.5.7 Questions
- Que gagne-t-on avec un graphique ?
- Quelles limites conserve-t-il ?
NoteVoir les réponses
Le graphique permet de voir rapidement quelles modalités sont les plus fréquentes.
Il facilite la lecture de la distribution et rend les écarts entre modalités plus visibles qu’un tableau d’effectifs.
En revanche, le graphique ne donne pas toujours directement :
- les effectifs exacts ;
- les pourcentages précis ;
- le sens détaillé des modalités ;
- les éventuels filtres du questionnaire.
Il faut donc toujours lire le graphique avec le dictionnaire des variables et les tableaux.
2.5.8 La modalité “Non concerné
On observe que la modalité 97 (“n’est pas concerné”) concerne seulement 3 individus dans la variable OA_REPAS.
2.5.9 Questions
- Est-ce beaucoup par rapport à l’effectif total ?
- Que peut-on faire de ces individus dans l’analyse ?
- Que ferait-on si cette modalité concernait une part beaucoup plus importante des individus ?
NoteVoir les réponses
La modalité 97 concerne seulement 3 individus sur 6 088.
C’est donc une part très faible de la population étudiée, sans impact majeur sur les résultats globaux.
On peut donc raisonnablement choisir de les exclure de l’analyse, à condition de le mentionner explicitement.
Mais ce choix reste une décision analytique.
Si cette modalité concernait une part beaucoup plus importante des individus, il faudrait d’abord comprendre son origine :
- situation réellement non concernée (par exemple, organisation spécifique du ménage) ;
- effet du questionnaire (filtre, formulation) ;
- ou caractéristique particulière de certains groupes sociaux.
Dans ce cas, il ne faudrait pas l’exclure automatiquement.
Il serait pertinent :
- d’analyser le profil des individus concernés ;
- de réfléchir à la signification de cette situation dans l’analyse ;
- et éventuellement de conserver une modalité spécifique.
2.5.9.1 Appliquer un traitement
TipVoir le code
# Exclure les individus avec la modalité 97
ERFI_couple_filtre <- ERFI_couple[ERFI_couple$OA_REPAS != 97, ]2.6 7. Croiser les variables
2.6.1 Introduire la variable sexe
Construire le tableau croisant : - OA_REPAS
- MA_SEXE
TipVoir le code
#Effectifs
table(ERFI_couple$MA_SEXE, ERFI_couple$OA_REPAS)
1 2 3 4 5 6 7 97
1 135 159 462 814 1241 4 6 2
2 1774 740 491 176 68 9 6 1#Pourcentage
prop.table(
table(ERFI_couple$MA_SEXE, ERFI_couple$OA_REPAS),
margin = 1
) * 100
1 2 3 4 5 6
1 4.78214665 5.63230606 16.36556854 28.83457315 43.96032589 0.14169323
2 54.33384380 22.66462481 15.03828484 5.39050536 2.08269525 0.27565084
7 97
1 0.21253985 0.07084662
2 0.18376723 0.03062787# margin = 1 → on calcule les proportions par ligne (100% pour les lignes, hommes ou femmes)2.6.2 Questions
- Que change ce tableau ?
- Les réponses sont-elles les mêmes selon le sexe ?
- Pourquoi ce croisement est indispensable ?
- Quelles sont les limites de ce tableau ?
NoteVoir les réponses
Le croisement entre OA_REPAS et MA_SEXE change l’interprétation.
Il permet de comprendre ce que signifie “moi” selon le sexe du répondant.
Les réponses ne sont pas les mêmes selon le sexe :
- parmi les hommes, les modalités “mon conjoint” sont très fréquentes ;
- parmi les femmes, les modalités “moi” sont très fréquentes.
Ce croisement est indispensable, car la variable OA_REPAS est formulée du point de vue de la personne enquêtée.
La limite du tableau est qu’il reste assez difficile à lire directement : il faut encore transformer les modalités pour répondre plus clairement à la question “qui fait la tâche ?”.
2.7 8. Recoder une variable
Objectif : transformer une réponse relative en réponse substantielle
Qui prépare les repas ?
- plutôt femme
- plutôt homme
- partagé
- autre personne
Créer la variable `repas_genre``.
TipVoir le code
# Code pour construire la variable repas_genre
ERFI_couple$repas_genre <- case_when(
# Cas 1 : la tâche est déclarée comme partagée
ERFI_couple$OA_REPAS == 3 ~ "Partagé",
# Cas 2 : la tâche est plutôt réalisée par une femme
# - si l'enquêté·e est une femme (MA_SEXE == 2) et répond "toujours" ou "le plus souvent moi"
# - ou si l'enquêté·e est un homme (MA_SEXE == 1) et répond "le plus souvent" ou "toujours mon conjoint"
ERFI_couple$MA_SEXE == 2 & ERFI_couple$OA_REPAS %in% c(1,2) ~ "Plutôt femme",
ERFI_couple$MA_SEXE == 1 & ERFI_couple$OA_REPAS %in% c(4,5) ~ "Plutôt femme",
# Cas 3 : la tâche est plutôt réalisée par un homme
# - si l'enquêté·e est un homme (MA_SEXE == 1) et répond "toujours" ou "le plus souvent moi"
# - ou si l'enquêté·e est une femme (MA_SEXE == 2) et répond "le plus souvent" ou "toujours mon conjoint"
ERFI_couple$MA_SEXE == 1 & ERFI_couple$OA_REPAS %in% c(1,2) ~ "Plutôt homme",
ERFI_couple$MA_SEXE == 2 & ERFI_couple$OA_REPAS %in% c(4,5) ~ "Plutôt homme",
# Cas 4 : la tâche est réalisée par quelqu’un d’autre (dans ou hors du ménage)
ERFI_couple$OA_REPAS %in% c(6,7) ~ "Autre personne",
# Cas par défaut : valeur manquante ou non traitée (ex : modalité 97)
TRUE ~ NA_character_
)
# Vérifier le résultat
table(ERFI_couple$repas_genre)
Autre personne Partagé Plutôt femme Plutôt homme
25 953 4569 538 prop.table(table(ERFI_couple$repas_genre)) * 100
Autre personne Partagé Plutôt femme Plutôt homme
0.4108463 15.6614626 75.0862777 8.8414133 # Visualiser
barplot(
table(ERFI_couple$repas_genre),
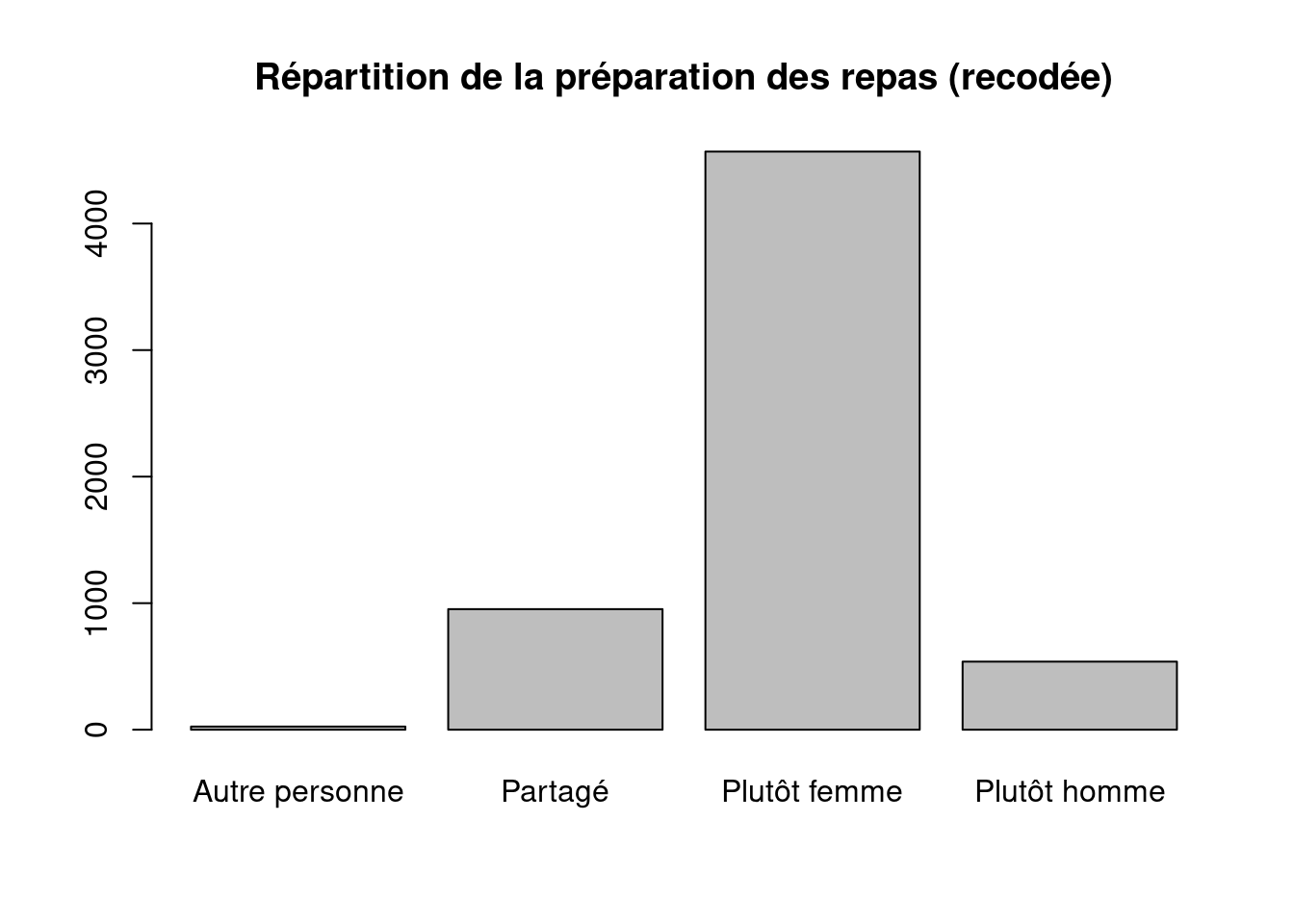
main = "Répartition de la préparation des repas (recodée)"
)
2.7.1 Questions
- Quelle catégorie domine ?
- La répartition est-elle équilibrée ?
- Que montre ce graphique ?
NoteVoir les réponses
La catégorie qui domine très largement est “Plutôt femme”.
Avec le recodage, on obtient environ :
- 75,1 % “Plutôt femme” ;
- 15,7 % “Partagé” ;
- 8,8 % “Plutôt homme” ;
- 0,4 % “Autre personne”.
La répartition n’est donc pas équilibrée.
Le graphique montre que la préparation des repas est très majoritairement déclarée comme étant plutôt réalisée par les femmes dans les couples observés.
NoteConstruire une variable
Ce qu’on vient de faire :une étape clé en statistique, c’est à dire transformer les données
- on ne se contente pas de lire
- on reconstruit une variable
Les données ne sont pas “données”
- Elles sont construites
- Elles doivent être interprétées
- Elles peuvent être transformées
2.7.2 Discuter les choix de recodage
Le recodage précédent est une première solution possible.
Mais ce choix n’est pas le seul possible. Quel autre type de recodage est possible?
2.7.3 Construire un second recodage
TipVoir la réponse
Pour construire la variable repas_genre2, les modalités :
6: toujours ou le plus souvent d’autres membres du ménage ;7: toujours ou le plus souvent quelqu’un ne faisant pas partie du ménage;
on été regroupées dans une catégorie “Autre personne”
Mais on pourrait aussi considérer que, du point de vue du partage entre conjoints, une tâche réalisée par une autre personne n’est ni plutôt féminine, ni plutôt masculine. Dans ce cas, on pourait aussi rapprocher ces tâches de la catégorie Partagé.
Cela ne veut pas dire que la tâche est réellement partagée entre conjoints. Cela signifie seulement que l’on décide de la coder comme une situation neutre dans le couple.
Construire la variable repas_genre2 selon cette nouvelle logique de recodage.
TipVoir le code
# Construction de la variable repas_genre2
ERFI_couple$repas_genre2 <- case_when(
# Cas 1 : tâche partagée entre les deux membres du couple
ERFI_couple$OA_REPAS == 3 ~ "Partagé",
# Cas 2 : tâche réalisée par une autre personne (dans ou hors du ménage)
# → on considère ici que cela ne renvoie pas à une répartition homme/femme
ERFI_couple$OA_REPAS %in% c(6,7) ~ "Partagé",
# Cas 3 : tâche plutôt réalisée par une femme
# - si l’enquêté·e est une femme et déclare "moi"
# - ou si l’enquêté·e est un homme et déclare "mon conjoint"
ERFI_couple$MA_SEXE == 2 & ERFI_couple$OA_REPAS %in% c(1,2) ~ "Plutôt femme",
ERFI_couple$MA_SEXE == 1 & ERFI_couple$OA_REPAS %in% c(4,5) ~ "Plutôt femme",
# Cas 4 : tâche plutôt réalisée par un homme
# - si l’enquêté·e est un homme et déclare "moi"
# - ou si l’enquêté·e est une femme et déclare "mon conjoint"
ERFI_couple$MA_SEXE == 1 & ERFI_couple$OA_REPAS %in% c(1,2) ~ "Plutôt homme",
ERFI_couple$MA_SEXE == 2 & ERFI_couple$OA_REPAS %in% c(4,5) ~ "Plutôt homme",
# Cas par défaut : valeurs manquantes ou non concernées (ex : 97)
TRUE ~ NA_character_
)
# Vérifier la distribution (effectifs)
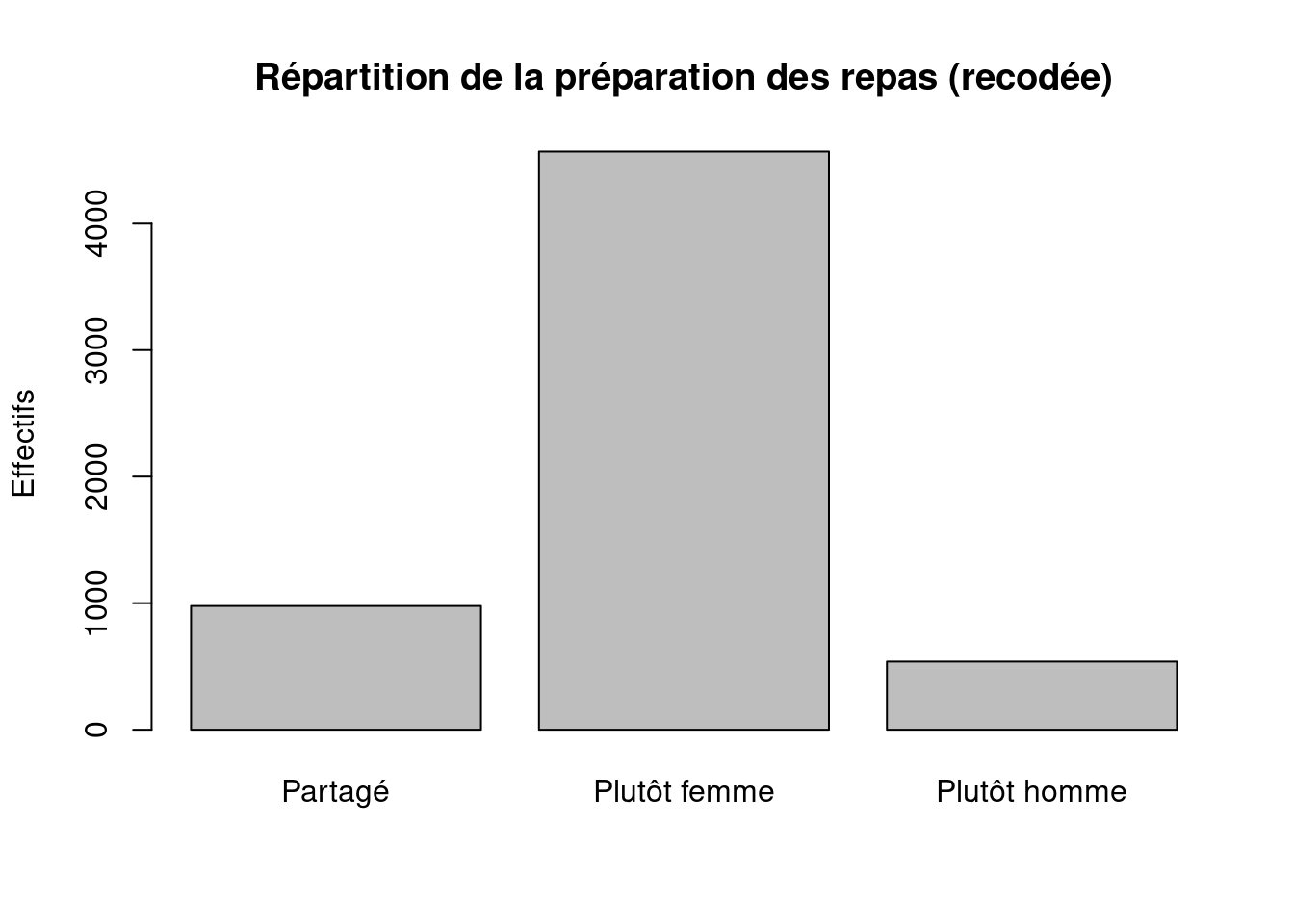
table(ERFI_couple$repas_genre2)
Partagé Plutôt femme Plutôt homme
978 4569 538 # Vérifier la distribution (en pourcentage)
round(
prop.table(table(ERFI_couple$repas_genre2)) * 100,
1
)
Partagé Plutôt femme Plutôt homme
16.1 75.1 8.8 # Visualiser la distribution
barplot(
table(ERFI_couple$repas_genre2),
main = "Répartition de la préparation des repas (recodée)",
ylab = "Effectifs"
)
2.7.4 Comparer les recodages
On compare la distribution obtenue selon les deux variables
# Recodage avec catégorie "Autre personne"
table(ERFI_couple$repas_genre)
Autre personne Partagé Plutôt femme Plutôt homme
25 953 4569 538 round(
prop.table(table(ERFI_couple$repas_genre)) * 100,
1
)
Autre personne Partagé Plutôt femme Plutôt homme
0.4 15.7 75.1 8.8 # Recodage avec "Autre personne" comme situation neutre
table(ERFI_couple$repas_genre2)
Partagé Plutôt femme Plutôt homme
978 4569 538 round(
prop.table(table(ERFI_couple$repas_genre2)) * 100,
1
)
Partagé Plutôt femme Plutôt homme
16.1 75.1 8.8 2.7.5 Questions
- Les résultats changent-ils beaucoup ?
- Pourquoi ?
- Dans quel cas l’écart pourrait-il être plus important ?
- Quel recodage vous semble le plus cohérent ?
- Quel recodage vous semble le plus simple à interpréter ?
NoteVoir les réponses
Les résultats changent très peu entre les deux recodages.
Dans le premier recodage, “Autre personne” représente seulement 0,4 % des cas.
Dans le second recodage, ces cas sont regroupés avec “Partagé”, ce qui fait passer cette catégorie d’environ 15,7 % à 16,1 %.
L’écart est faible parce que les modalités 6 et 7 concernent très peu d’individus.
L’écart pourrait être beaucoup plus important si une part importante des ménages déléguait la préparation des repas à une autre personne.
Le recodage le plus cohérent dépend de la question :
- si l’on veut distinguer la délégation des tâches, il faut garder “Autre personne” ;
- si l’on veut analyser les inégalités au sein du couple, on peut considérer “Autre personne” comme une situation neutre et la regrouper avec “Partagé”.
En effet, si la tâche est réalisée par une autre personne :
- elle ne pèse ni sur l’homme ni sur la femme ;
- elle peut donc être interprétée comme une manière de réduire l’inégalité dans le couple.
Mais ce choix a des implications :
- déléguer une tâche n’est pas la même chose que la partager ;
- cela renvoie à d’autres dimensions (ressources, organisation, externalisation du travail domestique).
Ainsi :
- le premier recodage est plus précis (il distingue la délégation) ;
- le second est plus directement aligné avec une question d’inégalité entre conjoints.
Il n’y a pas un seul “bon” recodage : tout dépend de ce que l’on cherche à mesurer.
NoteCe que montre cet exemple
À partir d’une même variable, on peut produire plusieurs variables d’analyse.
Ce choix peut modifier ce que l’on observe.
Dans cet exemple, on a regroupé les modalités en grandes catégories :
Plutôt femme;Plutôt homme;Partagé;- éventuellement
Autre personne.
Mais on aurait aussi pu faire d’autres choix, par exemple :
- isoler les situations où la tâche est toujours réalisée par la femme ;
- isoler les situations où la tâche est toujours réalisée par l’homme ;
- isoler les situations où la tâche est réalisée par une autre personne ;
- comparer les situations “toujours” aux situations “le plus souvent”.
Ces choix peuvent être pertinents si l’analyse porte spécifiquement sur les situations les plus inégalitaires, sur la délégation des tâches, ou sur les formes intermédiaires du partage.
Il faut donc toujours :
- comprendre les modalités d’origine ;
- choisir les regroupements en fonction de la question posée ;
- justifier les regroupements ;
- vérifier si les résultats changent ;
- documenter les choix réalisés.
Il n’y a pas un seul “bon” recodage : tout dépend de l’objectif de l’analyse.
NotePoint clé
Une analyse statistique ne commence pas par un test, ou par des calculs compliqués.
Elle commence par des questions simples :
- qui est observé ?
- qui est concerné ?
- que mesure la variable ?
- que faire des données manquantes ?
- quelles modalités faut-il traiter avec prudence ?
- quels choix de recodage ?
Les calculs viennent après.
Le raisonnement vient avant.
3 EXERCICE 3 Correction
Jusqu’ici, nous avons travaillé principalement sur une seule tâche : la préparation des repas.
Mais les mêmes questions se posent pour les autres tâches domestiques.
L’objectif est de vérifier si la modalité 97 apparaît aussi dans les autres variables de tâches.
3.1 1. Explorer l’ensemble des tâches domestiques
3.1.1 Identifier les variables de tâches
On commence par créer la liste des variables correspondant aux tâches domestiques.
TipVoir le code
vars_taches <- c(
"OA_REPAS",
"OA_VAISS",
"OA_LINGE",
"OA_COMPT",
"OA_BRICO",
"OA_ASPIR",
"OA_ALIME"
)3.1.2 Observer les distributions
On regarde ensuite la distribution de chaque variable.
TipVoir le code
# On utilise ici une boucle pour répéter la même opération sur plusieurs variables.
# On parcourt la liste des variables une par une
for (var in vars_taches) {
# À chaque tour de boucle :
# → 'var' prend le nom d'une variable (ex : "OA_REPAS", puis "OA_VAISS", etc.)
# On affiche un séparateur pour bien distinguer les résultats
cat("\n====================\n")
# On affiche le nom de la variable en cours
cat("Variable :", var, "\n")
# On calcule et affiche la distribution de cette variable
# ERFI_couple[[var]] permet d'accéder à la variable dont le nom est stocké dans 'var'
print(
table(ERFI_couple[[var]], useNA = "always")
)
}
====================
Variable : OA_REPAS
1 2 3 4 5 6 7 97 <NA>
1909 899 953 990 1309 13 12 3 0
====================
Variable : OA_VAISS
1 2 3 4 5 6 7 97 <NA>
1321 851 2003 807 890 78 17 121 0
====================
Variable : OA_LINGE
1 2 3 4 5 6 7 97 <NA>
2594 276 341 416 2003 33 309 116 0
====================
Variable : OA_COMPT
1 2 3 4 5 6 7 97 <NA>
1926 484 1689 544 1408 12 21 4 0
====================
Variable : OA_BRICO
1 2 3 4 5 6 7 97 <NA>
1939 679 821 802 1657 19 121 50 0
====================
Variable : OA_ASPIR
1 2 3 4 5 6 7 97 <NA>
1576 776 1376 797 1115 59 324 65 0
====================
Variable : OA_ALIME
1 2 3 4 5 6 7 97 <NA>
1369 816 2358 714 796 16 17 2 0 3.1.3 Questions
- La modalité
97apparaît-elle pour toutes les tâches ?
- Certaines tâches ont-elles davantage de personnes “non concernées” ?
- À quoi cela peut-il correspondre concrètement ?
- Pourquoi faut-il repérer ces modalités avant de comparer les tâches ?
NoteVoir les réponses
La modalité 97 apparaît bien dans toutes les variables de tâches, mais avec des effectifs très différents selon les tâches.
Elle concerne notamment :
OA_REPAS: 3 individus ;OA_VAISS: 121 individus ;OA_LINGE: 116 individus ;OA_COMPT: 4 individus ;OA_BRICO: 50 individus ;OA_ASPIR: 65 individus ;OA_ALIME: 2 individus.
Certaines tâches ont donc davantage de personnes “non concernées”, notamment la vaisselle, le linge, l’aspirateur ou le bricolage.
Cela peut correspondre à des situations concrètes où la tâche n’existe pas vraiment dans le ménage, est externalisée, ou ne se pose pas de la même manière selon les conditions de vie.
Il faut repérer ces modalités avant de comparer les tâches, car 97 ne signifie pas une répartition de la tâche entre les conjoints. Ce n’est ni “moi”, ni “mon conjoint”, ni “partagé”.
Si on la conserve comme une modalité ordinaire, on risque de comparer des choses qui n’ont pas le même sens.
NotePoint clé
Une modalité comme 97 n’est pas une simple valeur numérique.
Elle signifie ici : n’est pas concerné.
Elle ne doit donc pas être interprétée comme une réponse ordinaire sur la répartition de la tâche.
Avant de construire un indicateur ou de comparer plusieurs variables, il faut décider comment traiter ce type de modalité.
3.2 2. Créer une base de travail sans les cas “non concernés”
3.2.1 Identifier les individus concernés
Pour certaines analyses, on peut choisir de retirer les individus qui ont au moins une modalité 97 sur l’une des tâches étudiées. Cela permet de travailler sur une base où toutes les tâches retenues concernent effectivement les individus.
Mais cette décision doit être discutée et documentée.
3.3 Repérer les individus concernés par au moins une modalité 97
TipVoir le code
#On construit ici une variable qui compte, pour chaque individu, le nombre de tâches pour lesquelles il/elle est “non concerné·e” (modalité 97).
# On crée une nouvelle variable dans la base
ERFI_couple$non_concerne_tache <- rowSums(
# ERFI_couple[vars_taches] sélectionne uniquement les variables de tâches domestiques
# (repas, vaisselle, linge, etc.)
ERFI_couple[vars_taches] == 97,
# '== 97' transforme les valeurs en TRUE / FALSE :
# → TRUE si la modalité est 97 ("non concerné")
# → FALSE sinon
# rowSums() additionne ligne par ligne :
# → TRUE = 1 et FALSE = 0
# → on obtient donc le nombre de tâches "non concerné" pour chaque individu
na.rm = TRUE # ignore les valeurs manquantes (NA)
)
# On regarde la distribution de cette nouvelle variable
table(ERFI_couple$non_concerne_tache, useNA = "always")
0 1 2 3 <NA>
5765 289 30 4 0 3.3.1 Construire une nouvelle base
Créer la base ERFI_couple_taches sans ces cas
TipVoir le code
#On restreint ici la base aux individus concernés par toutes les tâches domestiques.
# On crée une nouvelle base de données
ERFI_couple_taches <- ERFI_couple |>
# filter() permet de garder seulement certaines observations (lignes)
filter(non_concerne_tache == 0)
# → on conserve uniquement les individus pour lesquels
# le nombre de tâches "non concerné" est égal à 0
# → donc des individus concernés par toutes les tâches étudiées3.3.2 Comparer avant / après filtrage
TipVoir le code
# Nombre total d’individus vivant en couple (avant filtrage)
nrow(ERFI_couple)[1] 6088# Nombre d’individus après avoir exclu ceux avec au moins une modalité 97
nrow(ERFI_couple_taches)[1] 5765# Nombre d’individus exclus par ce filtrage
# → différence entre la taille avant et après filtrage
nrow(ERFI_couple) - nrow(ERFI_couple_taches)[1] 3233.3.3 Vérifier le résultat
TipVoir le code
# On parcourt toutes les variables de tâches domestiques
for (var in vars_taches) {
# Afficher un séparateur pour mieux lire les résultats
cat("\n====================\n")
# Afficher le nom de la variable en cours
cat("Variable :", var, "\n")
# Afficher la distribution des modalités
# → on vérifie notamment que la modalité 97 n’apparaît plus
print(
table(ERFI_couple_taches[[var]], useNA = "always")
)
}
====================
Variable : OA_REPAS
1 2 3 4 5 6 7 <NA>
1832 848 878 930 1255 12 10 0
====================
Variable : OA_VAISS
1 2 3 4 5 6 7 <NA>
1289 825 1925 776 862 72 16 0
====================
Variable : OA_LINGE
1 2 3 4 5 6 7 <NA>
2516 265 326 398 1938 31 291 0
====================
Variable : OA_COMPT
1 2 3 4 5 6 7 <NA>
1834 451 1606 508 1339 11 16 0
====================
Variable : OA_BRICO
1 2 3 4 5 6 7 <NA>
1847 646 782 762 1597 14 117 0
====================
Variable : OA_ASPIR
1 2 3 4 5 6 7 <NA>
1530 741 1303 760 1076 51 304 0
====================
Variable : OA_ALIME
1 2 3 4 5 6 7 <NA>
1310 756 2230 676 768 12 13 0 3.3.4 Questions
- Combien d’individus sont retirés parce qu’ils ont au moins une tâche codée
97?
- Cette exclusion vous paraît-elle justifiée ?
- Cette décision peut-elle influencer les résultats ?
- Dans quel cas faudrait-il plutôt conserver ces individus dans une catégorie à part ?
- Comment documenteriez-vous ce choix dans un rapport ?
NoteVoir les réponses
La variable non_concerne_tache compte, pour chaque individu, le nombre de tâches pour lesquelles la modalité 97 apparaît.
Les résultats montrent que :
- 5 765 individus n’ont aucune tâche codée
97; - 289 individus ont une tâche codée
97; - 30 individus ont deux tâches codées
97; - 4 individus ont trois tâches codées
97.
Au total, 323 individus ont au moins une tâche codée 97.
NoteVoir les réponses
Avant filtrage, la base contient 6 088 individus vivant en couple.
Après exclusion des individus ayant au moins une tâche codée 97, il reste 5 765 individus, soit 323 individus exclus (≈ 5,3 %).
Ce filtrage permet de travailler sur une population comparable pour toutes les tâches, mais il n’est pas neutre :
- il réduit la population étudiée ;
- il peut modifier les résultats si les individus exclus ont des caractéristiques particulières.
Point important :
- lorsque le nombre d’individus exclus est non négligeable, il faut examiner leurs caractéristiques (type de ménage, présence d’enfants, etc.) pour vérifier qu’ils ne forment pas un groupe spécifique.
Deux options selon l’objectif :
- exclure pour comparer strictement les tâches ;
- conserver dans une catégorie spécifique si “non concerné” a un sens analytique.
Dans tous les cas, il faut :
- indiquer combien d’individus sont exclus ;
- justifier le choix ;
- préciser la population finale d’analyse.
Dans un rapport, il faudrait documenter clairement le choix effectué.
On pourrait écrire par exemple :
L’analyse porte sur les individus vivant avec un conjoint et concernés par l’ensemble des tâches domestiques étudiées. Les individus ayant au moins une tâche codée
97(“n’est pas concerné”) ont été exclus de cette partie de l’analyse. Ce filtrage conduit à retirer 323 individus, soit environ 5,3 % des 6 088 individus vivant en couple. L’échantillon d’analyse comprend donc 5 765 individus.
Il faudrait aussi préciser que cette décision est liée à l’objectif de comparer les tâches entre elles sur une population commune.
Après avoir filtré la base, il faut vérifier la population sur laquelle on travaille.
On ne travaille plus sur l’ensemble des individus enquêtés, mais sur les personnes :
- vivant avec un conjoint ;
- concernées par toutes les tâches domestiques retenues.
3.4 3. Comparez les individus conservés et exclus : âge, sexe, type de ménage.
Le filtrage que l’on vient d’effectuer n’est pas neutre. Il est donc important de vérifier si les individus exclus sont différents des autres.
On compare ici rapidement les individus :
- conservés (non_concerne_tache == 0)
- exclus (non_concerne_tache > 0)
3.4.1 Comparer selon le sexe, le type de ménage et l’âge
Séparément selon le sexe, le type de ménage, puis l’âge.
TipVoir le code
# Comparer selon le sexe
table(ERFI_couple$MA_SEXE, ERFI_couple$non_concerne_tache == 0)
FALSE TRUE
1 148 2675
2 175 3090prop.table(
table(ERFI_couple$MA_SEXE, ERFI_couple$non_concerne_tache == 0),
margin = 2
) * 100
FALSE TRUE
1 45.82043 46.40069
2 54.17957 53.59931# Comparer selon le type de ménage
table(ERFI_couple$TYPFAM3_rec, ERFI_couple$non_concerne_tache == 0)
FALSE TRUE
3 140 2824
4 183 2941prop.table(
table(ERFI_couple$TYPFAM3_rec, ERFI_couple$non_concerne_tache == 0),
margin = 2
) * 100
FALSE TRUE
3 43.34365 48.98526
4 56.65635 51.01474# Comparer selon l'âge
tapply(
ERFI_couple$MA_AGEM_rec,
ERFI_couple$non_concerne_tache == 0,
mean,
na.rm = TRUE
) FALSE TRUE
44.34056 48.43452 tapply(
ERFI_couple$MA_AGEM_rec,
ERFI_couple$non_concerne_tache == 0,
median,
na.rm = TRUE
)FALSE TRUE
42 48 3.4.2 Questions
- Les individus exclus ont-ils le même profil que les individus conservés ?
- Observe-t-on des différences selon le sexe ? le type de ménage ? l’âge ?
- Le filtrage vous semble-t-il neutre… ou susceptible de biaiser l’analyse ?
NoteVoir les réponses
Les individus exclus et conservés ont un profil très proche selon le sexe.
Parmi les individus exclus :
- 45,8 % sont des hommes ;
- 54,2 % sont des femmes.
Parmi les individus conservés :
- 46,4 % sont des hommes ;
- 53,6 % sont des femmes.
Le filtrage ne semble donc pas modifier fortement la répartition par sexe.
En revanche, on observe davantage de différences selon le type de ménage et l’âge.
Les individus exclus sont un peu plus souvent en couple avec enfant(s) :
- 56,7 % des exclus vivent en couple avec enfant(s) ;
- contre 51,0 % des individus conservés.
Ils sont aussi plus jeunes :
- âge moyen des exclus : 44,3 ans ;
- âge moyen des conservés : 48,4 ans ;
- âge médian des exclus : 42 ans ;
- âge médian des conservés : 48 ans.
Le filtrage n’est donc pas totalement neutre : il exclut légèrement davantage d’individus plus jeunes et vivant en couple avec enfant(s).
Cela peut influencer les résultats si ces caractéristiques sont liées à la répartition des tâches domestiques.
Même lorsqu’un filtrage semble raisonnable, il faut vérifier qui l’on retire de l’analyse.
3.5 4. Explorer l’âge des enquêté.es
3.5.1 Résumer la variable âge
On observe maintenant l’âge des individus de la base ERFI_couple_taches.
La variable utilisée est MA_AGEM_rec, qui indique l’âge de l’enquêté·e au 31 décembre 2005.
TipVoir le code
# Résumer la variable d'âge
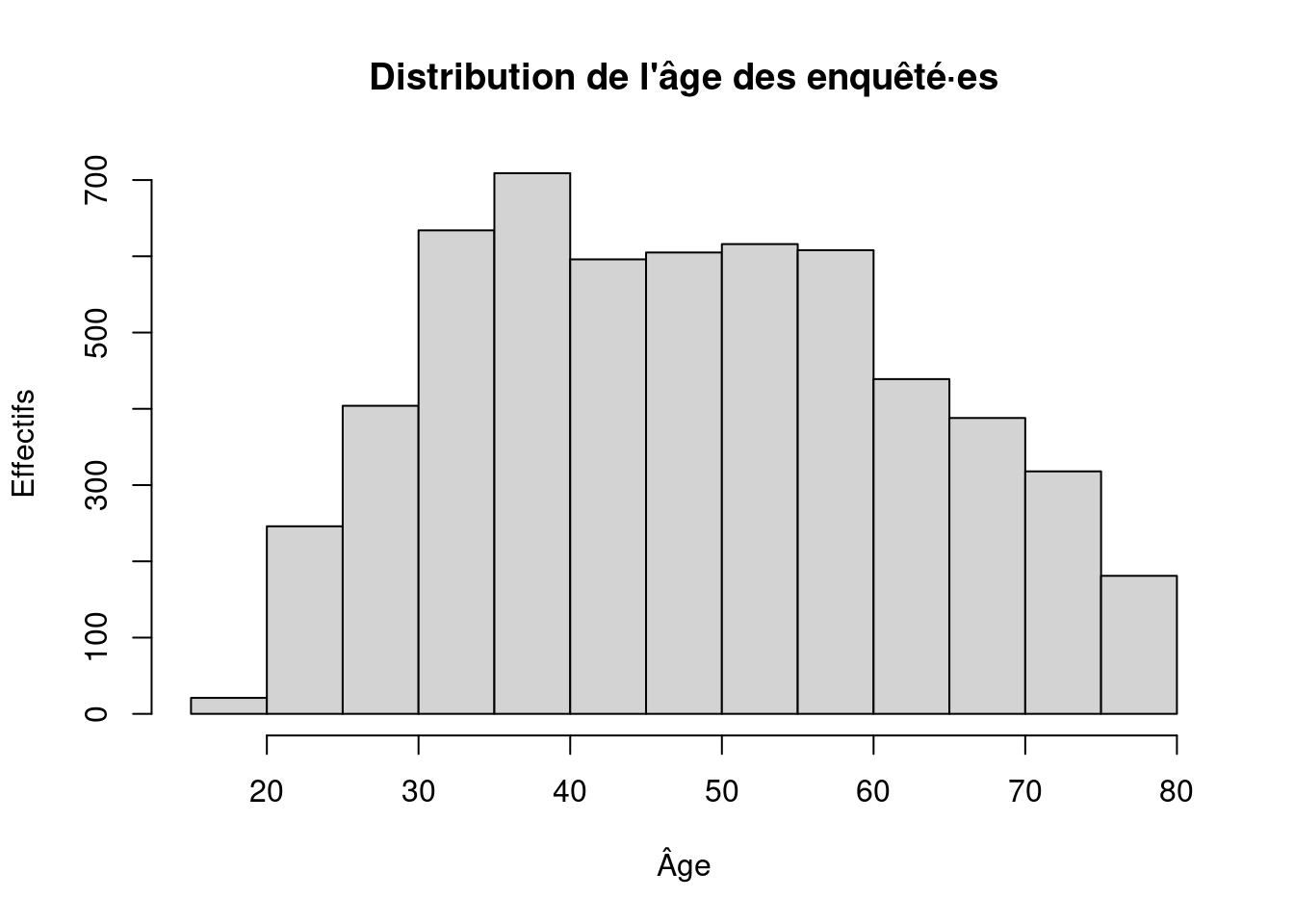
summary(ERFI_couple_taches$MA_AGEM_rec) Min. 1st Qu. Median Mean 3rd Qu. Max.
18.00 36.00 48.00 48.43 59.00 79.00 # Visualiser la distribution de l'âge
hist(
ERFI_couple_taches$MA_AGEM_rec,
main = "Distribution de l'âge des enquêté·es",
xlab = "Âge",
ylab = "Effectifs"
)
3.5.2 Questions
- Quel est l’âge minimum observé ?
- Quel est l’âge maximum observé ?
- Où se situe la médiane ?
- La population étudiée semble-t-elle plutôt jeune, âgée, ou diversifiée ?
NoteVoir les réponses
L’âge minimum observé est de 18 ans et le maximum de 79 ans.
La médiane est de 48 ans, ce qui signifie que la moitié des individus a moins de 48 ans et l’autre moitié plus.
La moyenne (48,4 ans) est très proche de la médiane, ce qui suggère une distribution relativement équilibrée, sans forte asymétrie.
La population apparaît donc diversifiée en âge, mais avec une concentration importante autour des âges intermédiaires (adultes d’âge moyen).
3.5.3 Construire des classes d’âge
Pour faciliter l’interprétation, on peut transformer l’âge en classes.
On construit ici une variable age_cat avec les catégories suivantes :
18-29 ans
30-44 ans
45-59 ans
60 ans et plus
TipVoir le code
# Construire une variable en classes d'âge
ERFI_couple_taches$age_cat <- cut(
ERFI_couple_taches$MA_AGEM_rec,
breaks = c(18, 30, 45, 60, 80),
right = FALSE,
labels = c("18-29 ans", "30-44 ans", "45-59 ans", "60 ans et plus")
)
# Vérifier la distribution
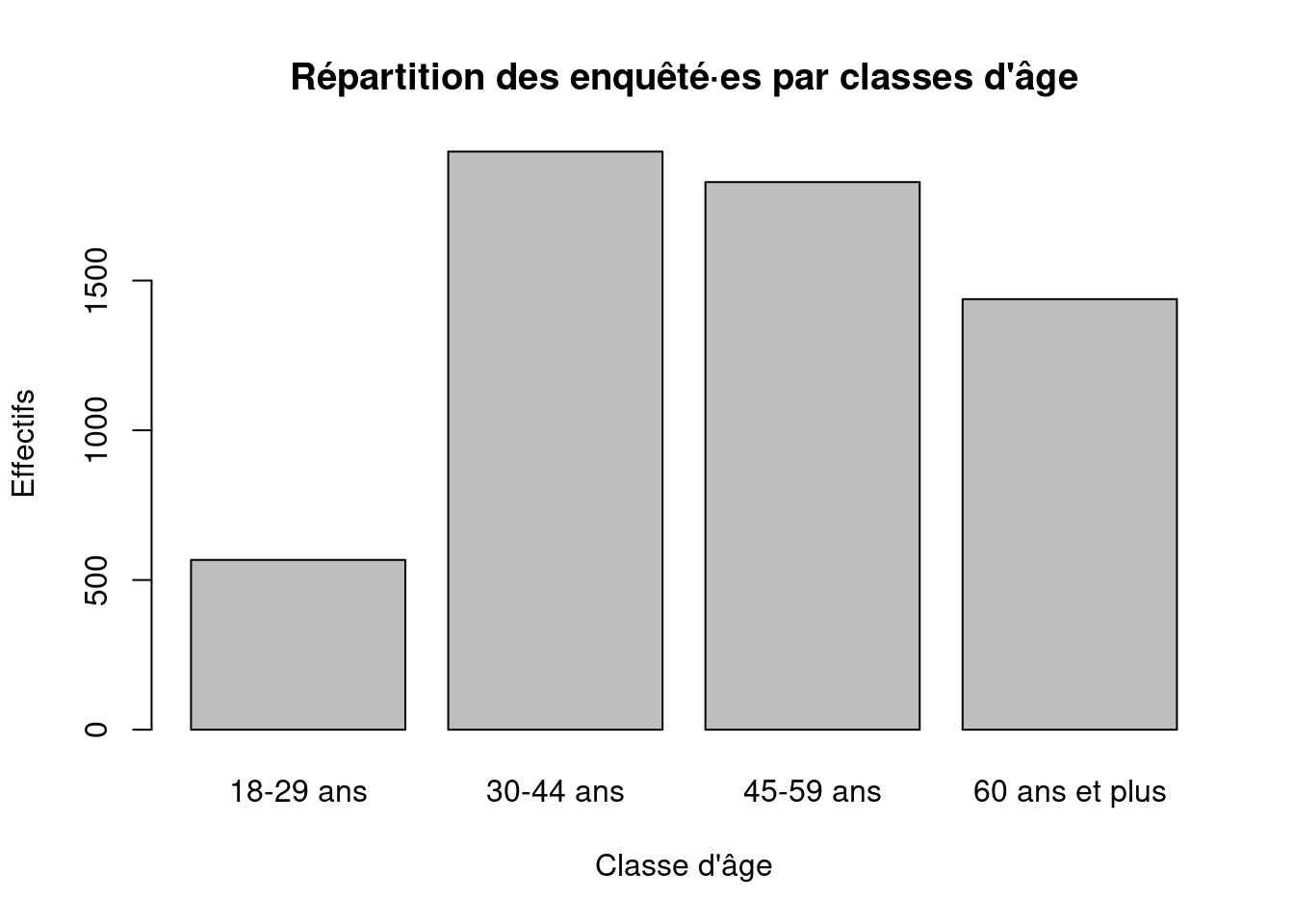
table(ERFI_couple_taches$age_cat, useNA = "always")
18-29 ans 30-44 ans 45-59 ans 60 ans et plus <NA>
567 1931 1829 1438 0 # Calculer les pourcentages
round(
prop.table(table(ERFI_couple_taches$age_cat)) * 100,
1
)
18-29 ans 30-44 ans 45-59 ans 60 ans et plus
9.8 33.5 31.7 24.9 # Visualiser les classes d’âge
barplot(
table(ERFI_couple_taches$age_cat),
main = "Répartition des enquêté·es par classes d'âge",
xlab = "Classe d'âge",
ylab = "Effectifs"
)
3.5.4 Questions
- Quelle classe d’âge est la plus représentée ?
- Les classes d’âge sont-elles équilibrées ?
- Que gagne-t-on avec des classes ?
- Que perd-on ?
- Pourquoi l’âge peut-il être intéressant pour analyser la répartition des tâches domestiques ?
NoteVoir les réponses
La classe d’âge la plus représentée est celle des 30-44 ans (33,5 %), suivie de près par les 45-59 ans (31,7 %).
Les 60 ans et plus représentent environ 24,9 %, tandis que les 18-29 ans sont nettement moins nombreux (9,8 %).
Les classes ne sont donc pas équilibrées : les jeunes sont sous-représentés, et la population est surtout composée d’adultes d’âge intermédiaire.
Transformer une variable en classes permet de :
- simplifier la lecture ;
- comparer plus facilement des groupes ;
- produire des analyses plus lisibles.
Mais cela implique aussi :
- une perte d’information (on ne distingue plus les âges précis) ;
- une dépendance aux choix de seuils, qui peuvent influencer les résultats.
L’âge est une variable importante pour analyser les tâches domestiques car il peut être lié :
- aux générations ;
- aux modes de vie ;
- à la présence d’enfants ;
- ou encore aux normes sociales concernant la répartition des rôles.
NotePoint de méthode
Transformer une variable numérique en classes peut faciliter la lecture et la comparaison entre groupes.
Mais ce choix n’est jamais neutre :
- les seuils choisis peuvent modifier les résultats ;
- on perd une partie de l’information initiale ;
- deux individus proches peuvent se retrouver dans deux catégories différentes.
Recoder une variable, c’est toujours faire un choix d’analyse.
3.6 5. Recoder les tâches domestiques
3.6.1 Construire des variables interprétables
On a construit une variable interprétable pour la préparation des repas.
On applique maintenant le même principe à toutes les tâches domestiques.
Objectif : créer des variables indiquant si la tâche est réalisée :
- plutôt par une femme
- plutôt par un homme
- conjointement
- par une autre personne
TipVoir le code
#On construit ici des variables recodées pour toutes les tâches domestiques, en utilisant une boucle.
# On parcourt la liste des variables de tâches une par une
for (var in vars_taches) {
# On crée le nom de la nouvelle variable
# ex : "OA_REPAS" → "OA_REPAS_genre"
nouvelle_var <- paste0(var, "_genre")
# On crée cette nouvelle variable dans la base
ERFI_couple_taches[[nouvelle_var]] <- case_when(
# Cas 1 : tâche partagée
ERFI_couple_taches[[var]] == 3 ~ "Partagé",
# Cas 2 : tâche plutôt réalisée par une femme
# → dépend du sexe de l’enquêté·e et de la réponse "moi / conjoint"
ERFI_couple_taches$MA_SEXE == 2 & ERFI_couple_taches[[var]] %in% c(1,2) ~ "Plutôt femme",
ERFI_couple_taches$MA_SEXE == 1 & ERFI_couple_taches[[var]] %in% c(4,5) ~ "Plutôt femme",
# Cas 3 : tâche plutôt réalisée par un homme
ERFI_couple_taches$MA_SEXE == 1 & ERFI_couple_taches[[var]] %in% c(1,2) ~ "Plutôt homme",
ERFI_couple_taches$MA_SEXE == 2 & ERFI_couple_taches[[var]] %in% c(4,5) ~ "Plutôt homme",
# Cas 4 : tâche réalisée par une autre personne
ERFI_couple_taches[[var]] %in% c(6,7) ~ "Autre personne",
# Cas par défaut : valeurs manquantes ou non concernées
TRUE ~ NA_character_
)
}3.6.2 Vérifier les variables créées
TipVoir le code
#On construit ici la liste des variables recodées, puis on vérifie qu’elles existent bien dans la base.
# On construit une liste des noms des variables recodées
vars_genre <- paste0(vars_taches, "_genre")
# Afficher cette liste
vars_genre[1] "OA_REPAS_genre" "OA_VAISS_genre" "OA_LINGE_genre" "OA_COMPT_genre"
[5] "OA_BRICO_genre" "OA_ASPIR_genre" "OA_ALIME_genre"# Vérifier que ces variables existent bien dans la base de données
names(ERFI_couple_taches)[names(ERFI_couple_taches) %in% vars_genre][1] "OA_REPAS_genre" "OA_VAISS_genre" "OA_LINGE_genre" "OA_COMPT_genre"
[5] "OA_BRICO_genre" "OA_ASPIR_genre" "OA_ALIME_genre"3.6.3 Observer les distributions
TipVoir le code
#On affiche ici la distribution en pourcentage pour chaque variable recodée.
# On parcourt la liste des variables recodées une par une
for (var in vars_genre) {
# À chaque tour, 'var' prend le nom d’une variable
# ex : "OA_REPAS_genre", puis "OA_VAISS_genre", etc.
# Afficher un séparateur pour mieux lire les résultats
cat("\n====================\n")
# Afficher le nom de la variable en cours
cat("Variable :", var, "\n")
# Calculer et afficher la distribution en pourcentage
print(
round(
# prop.table() transforme les effectifs en proportions
prop.table(
# table() compte le nombre d’individus par modalité
table(ERFI_couple_taches[[var]])
) * 100, # transformation en pourcentage
1 # arrondi à 1 chiffre après la virgule
)
)
}
====================
Variable : OA_REPAS_genre
Autre personne Partagé Plutôt femme Plutôt homme
0.4 15.2 75.7 8.7
====================
Variable : OA_VAISS_genre
Autre personne Partagé Plutôt femme Plutôt homme
1.5 33.4 52.9 12.2
====================
Variable : OA_LINGE_genre
Autre personne Partagé Plutôt femme Plutôt homme
5.6 5.7 85.2 3.6
====================
Variable : OA_COMPT_genre
Autre personne Partagé Plutôt femme Plutôt homme
0.5 27.9 43.5 28.2
====================
Variable : OA_BRICO_genre
Autre personne Partagé Plutôt femme Plutôt homme
2.3 13.6 7.9 76.3
====================
Variable : OA_ASPIR_genre
Autre personne Partagé Plutôt femme Plutôt homme
6.2 22.6 60.4 10.9
====================
Variable : OA_ALIME_genre
Autre personne Partagé Plutôt femme Plutôt homme
0.4 38.7 49.5 11.3 3.6.4 Questions
- La répartition est-elle la même pour toutes les tâches ?
- Quelles tâches semblent les plus féminisées ?
- Quelles tâches semblent les plus masculinisées ?
- Quelles tâches semblent les plus partagées ?
- Certaines tâches sont-elles plus souvent réalisées par une autre personne ?
NoteVoir les réponses
Répartition des tâches
La répartition n’est pas la même selon les tâches.
- Tâches très féminisées :
- linge (≈ 85 %)
- repas (≈ 76 %)
- aspirateur (≈ 60 %)
- Tâches très masculinisées :
- bricolage (≈ 76 %)
- Tâches plus partagées :
- courses (≈ 39 % partagé)
- vaisselle (≈ 33 % partagé)
- comptes (≈ 28 % partagé)
Certaines tâches sont donc fortement genrées, d’autres plus équilibrées.
Cela suggère une division du travail domestique différenciée selon le type de tâche.
3.7 6. Comparer deux tâches
On compare deux tâches dont la répartition semble différente :
- la préparation des repas ;
- le bricolage.
3.7.1 Préparation des repas
TipVoir le code
#On décrit ici la variable `OA_REPAS_genre` de trois façons complémentaires.
# 1. Tableau des effectifs
table(ERFI_couple_taches$OA_REPAS_genre)
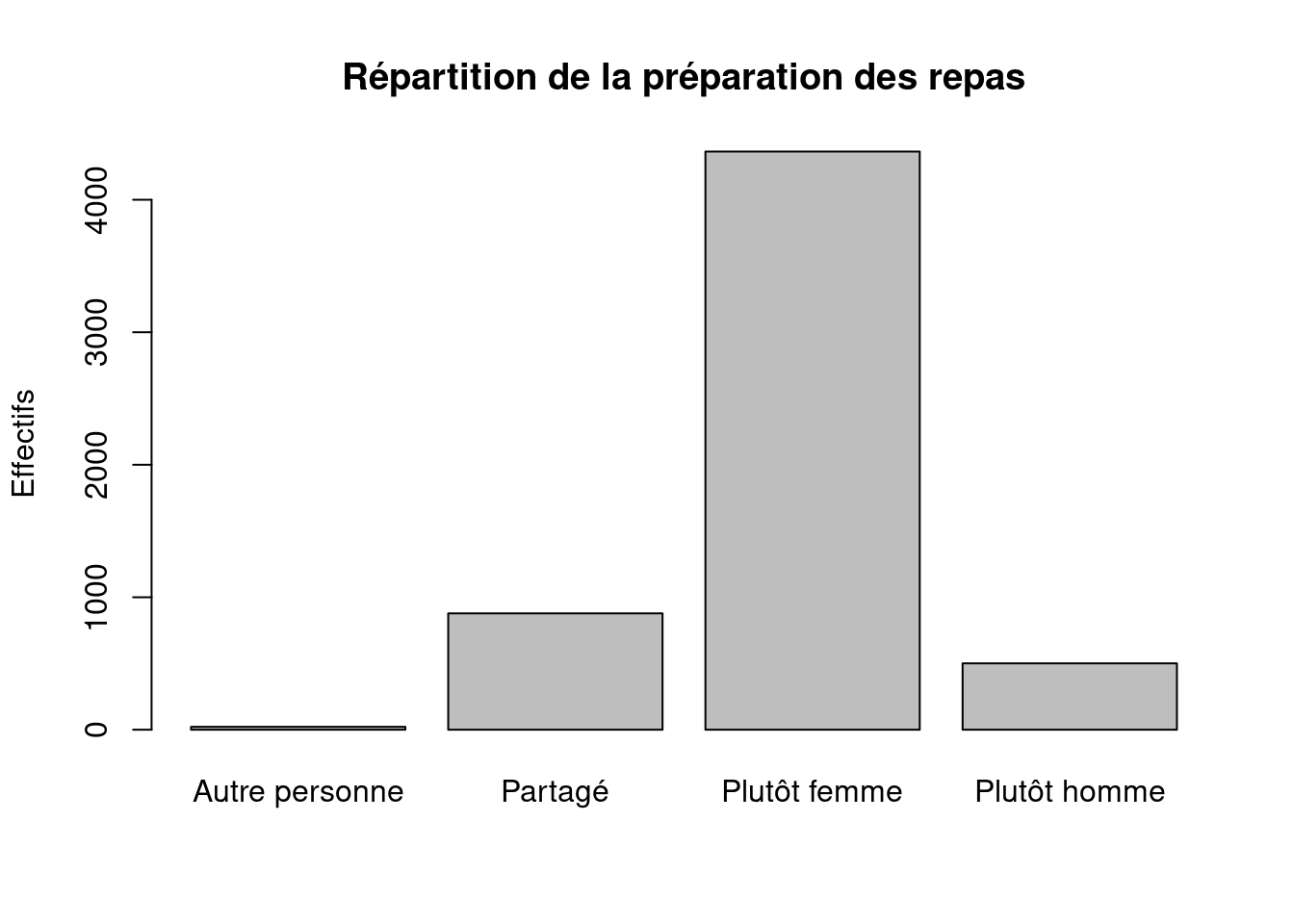
Autre personne Partagé Plutôt femme Plutôt homme
22 878 4364 501 # → compte le nombre d’individus dans chaque catégorie :
# "Plutôt femme", "Plutôt homme", "Partagé", etc.
# 2. Tableau en pourcentage
round(
prop.table(table(ERFI_couple_taches$OA_REPAS_genre)) * 100,
1
)
Autre personne Partagé Plutôt femme Plutôt homme
0.4 15.2 75.7 8.7 # → transforme les effectifs en pourcentages
# → permet de comparer les parts relatives
# 3. Représentation graphique
barplot(
table(ERFI_couple_taches$OA_REPAS_genre),
main = "Répartition de la préparation des repas",
ylab = "Effectifs"
)
# → représente les effectifs sous forme de barres
# → chaque barre correspond à une catégorie3.7.2 Bricolage
TipVoir le code
table(ERFI_couple_taches$OA_BRICO_genre)
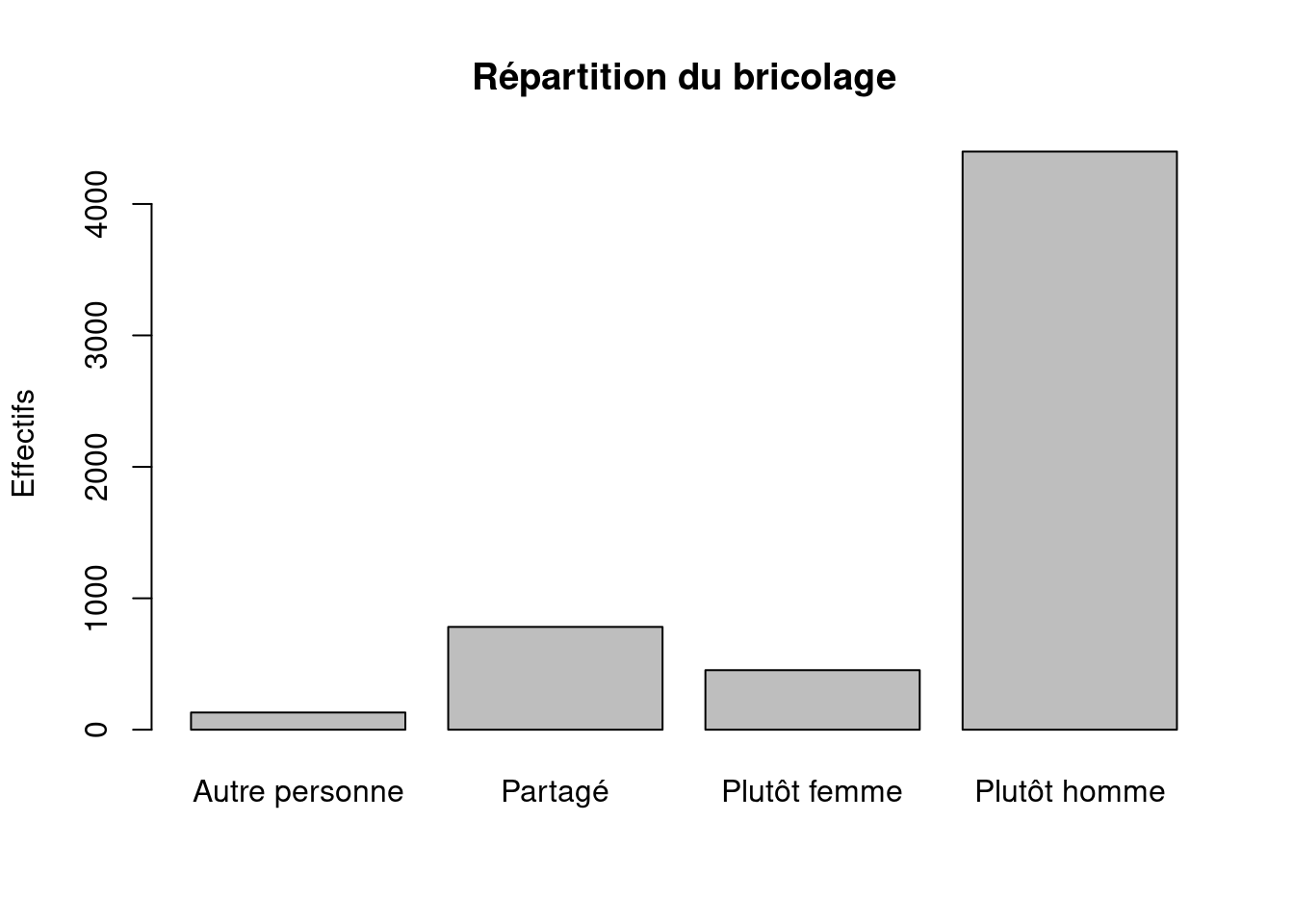
Autre personne Partagé Plutôt femme Plutôt homme
131 782 453 4399 round(
prop.table(table(ERFI_couple_taches$OA_BRICO_genre)) * 100,
1
)
Autre personne Partagé Plutôt femme Plutôt homme
2.3 13.6 7.9 76.3 barplot(
table(ERFI_couple_taches$OA_BRICO_genre),
main = "Répartition du bricolage",
ylab = "Effectifs"
)
3.7.3 Questions
- Le bricolage est-il réparti comme les repas ?
- Que suggère cette comparaison ?
- Peut-on déjà parler de division genrée des tâches ?
- Quelles précautions faut-il garder avant de conclure ?
NoteVoir les réponses
Comparaison repas / bricolage
Les repas sont très majoritairement réalisés par les femmes (≈ 76 %), alors que le bricolage est très majoritairement réalisé par les hommes (≈ 76 %).
La répartition est donc inversée selon la tâche. Cela suggère une division genrée des tâches domestiques.
Mais il faut rester prudent :
- ce sont des données déclaratives ;
- on ne tient pas compte d’autres facteurs (temps de travail, revenus, etc.) ;
- on ne mesure pas l’intensité ou la fréquence des tâches.
On peut formuler des hypothèses, mais pas conclure définitivement.
NotePoint clé
Comparer deux variables permet de faire apparaître des contrastes.
Mais une comparaison descriptive ne suffit pas à expliquer ces différences.
Elle permet surtout de formuler des hypothèses.
3.8 7. Construire un indicateur synthétique
Jusqu’ici, on a travaillé tâche par tâche.
On peut maintenant construire un indicateur synthétique qui résume la répartition des tâches domestiques au niveau du couple.
L’idée est de transformer chaque tâche en score numérique, puis d’additionner les scores.
3.8.1 Principe du score
Codage proposé :
+1: plutôt femme
0: partagée
-1: plutôt homme
0: autre personne
3.8.2 Questions
- Que signifie un score positif ?
- Que signifie un score négatif ?
- Pourquoi coder “partagé” à 0 ?
- Pourquoi coder “autre personne” à 0 ?
- Ce choix vous semble-t-il discutable ?
3.8.3 Transformer les variables en scores
TipVoir le code
#On transforme ici les variables recodées (qualitatives) en variables numériques, sous forme de score.
# On parcourt toutes les variables recodées (ex : OA_REPAS_genre, etc.)
for (var in vars_genre) {
# On crée le nom de la nouvelle variable de score
# ex : "OA_REPAS_genre" → "OA_REPAS_genre_score"
nouvelle_var <- paste0(var, "_score")
# On crée cette nouvelle variable dans la base
ERFI_couple_taches[[nouvelle_var]] <- case_when(
# Si la tâche est plutôt réalisée par une femme → score = +1
ERFI_couple_taches[[var]] == "Plutôt femme" ~ 1,
# Si la tâche est partagée → score = 0
ERFI_couple_taches[[var]] == "Partagé" ~ 0,
# Si la tâche est plutôt réalisée par un homme → score = -1
ERFI_couple_taches[[var]] == "Plutôt homme" ~ -1,
# Si la tâche est réalisée par une autre personne → score = 0 (neutre)
ERFI_couple_taches[[var]] == "Autre personne" ~ 0,
# Cas par défaut : valeur manquante
TRUE ~ NA_real_
)
}3.8.4 Vérifier les variables de score
TipVoir le code
#On construit ici la liste des variables de score créées précédemment.
# Créer la liste des variables de score
vars_scores <- paste0(vars_genre, "_score")
# Afficher cette liste
vars_scores[1] "OA_REPAS_genre_score" "OA_VAISS_genre_score" "OA_LINGE_genre_score"
[4] "OA_COMPT_genre_score" "OA_BRICO_genre_score" "OA_ASPIR_genre_score"
[7] "OA_ALIME_genre_score"# Vérifier que ces variables existent bien dans la base
names(ERFI_couple_taches)[names(ERFI_couple_taches) %in% vars_scores][1] "OA_REPAS_genre_score" "OA_VAISS_genre_score" "OA_LINGE_genre_score"
[4] "OA_COMPT_genre_score" "OA_BRICO_genre_score" "OA_ASPIR_genre_score"
[7] "OA_ALIME_genre_score"3.8.5 Construire le score total
TipVoir le code
#On construit ici un score total qui résume la répartition des tâches domestiques pour chaque individu.
# Calculer le score total
ERFI_couple_taches$score_total <- rowSums(
# On sélectionne toutes les variables de score (une par tâche)
ERFI_couple_taches[vars_scores],
# On ignore les valeurs manquantes (NA)
na.rm = TRUE
)3.8.6 Explorer le score
TipVoir le code
#On décrit ici la variable `score_total`, qui résume la répartition des tâches domestiques.
# Résumé statistique global
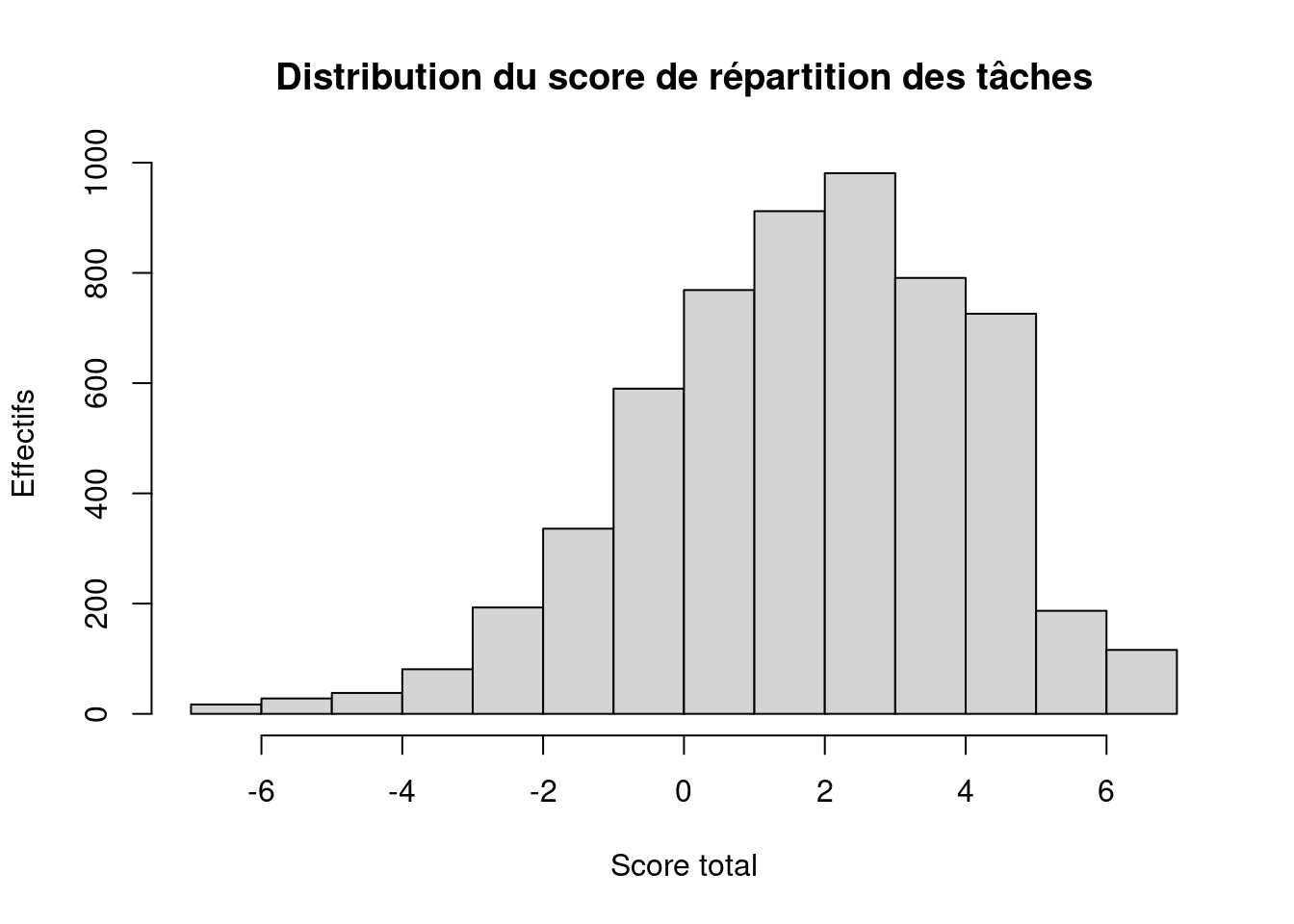
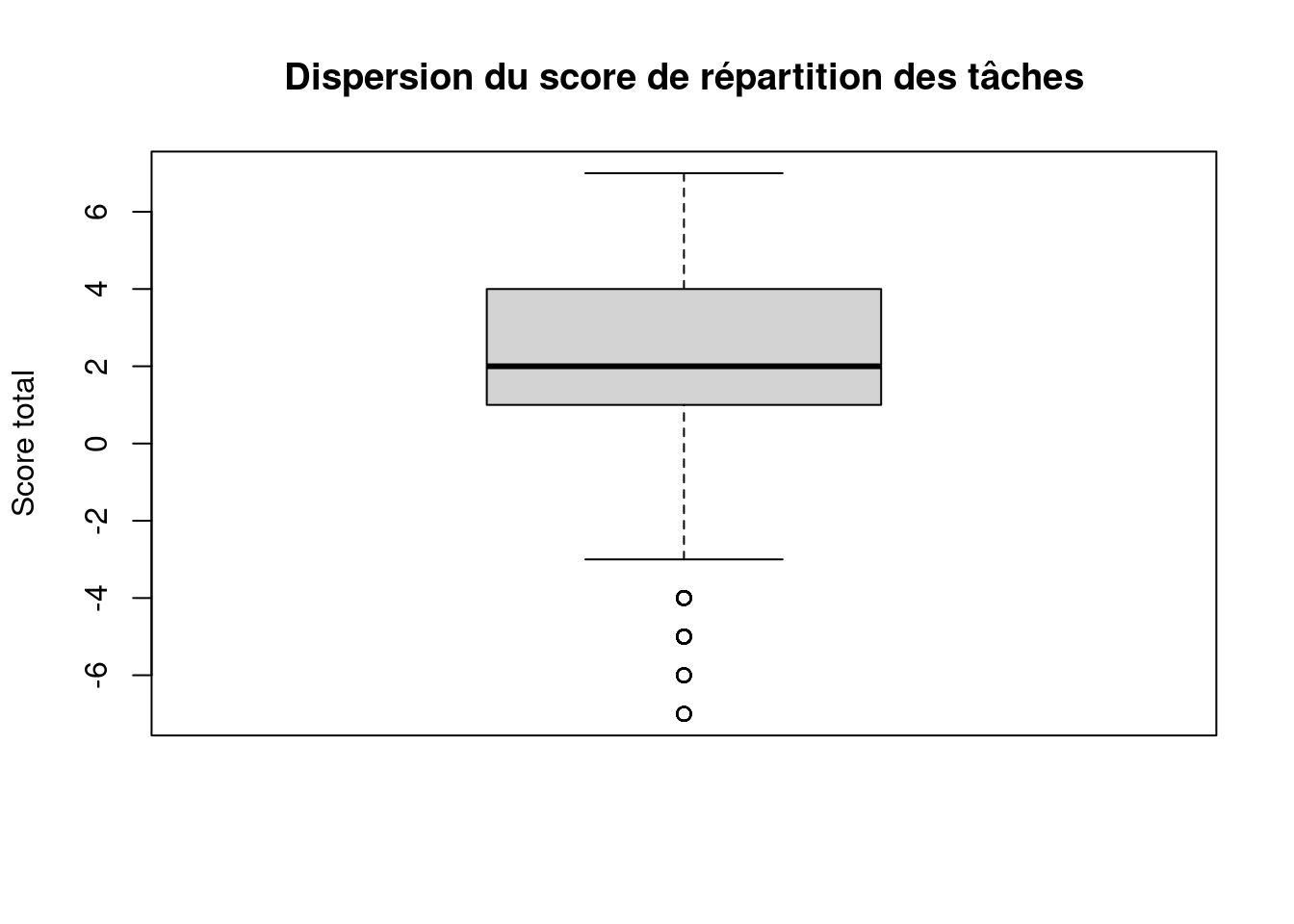
summary(ERFI_couple_taches$score_total) Min. 1st Qu. Median Mean 3rd Qu. Max.
-7.000 1.000 2.000 2.237 4.000 7.000 # → donne plusieurs indicateurs :
# minimum, maximum, médiane, moyenne, quartiles
# Moyenne du score
mean(ERFI_couple_taches$score_total, na.rm = TRUE)[1] 2.237121# → valeur moyenne du score dans la population
# Médiane du score
median(ERFI_couple_taches$score_total, na.rm = TRUE)[1] 2# → valeur qui partage la population en deux :
# 50 % en dessous, 50 % au-dessus
# Histogramme (distribution des valeurs)
hist(
ERFI_couple_taches$score_total,
main = "Distribution du score de répartition des tâches",
xlab = "Score total",
ylab = "Effectifs"
)
# → permet de visualiser la forme de la distribution :
# symétrie, concentration, valeurs extrêmes
# Boîte à moustaches (dispersion)
boxplot(
ERFI_couple_taches$score_total,
main = "Dispersion du score de répartition des tâches",
ylab = "Score total"
)
# → permet de visualiser :
# - la médiane
# - l’étendue des valeurs
# - les éventuelles valeurs atypiques3.8.7 Questions
- Quelle est la valeur minimale du score ?
- La valeur maximale ?
- Le score est-il plutôt positif ou proche de 0 ?
- Observe-t-on de la dispersion ?
- Un score égal à 0 signifie-t-il forcément que toutes les tâches sont partagées ?
TipVoir les réponses
Score de répartition des tâches
- score minimum : -7 (toutes les tâches plutôt masculines)
- score maximum : +7 (toutes les tâches plutôt féminines)
- moyenne ≈ 2,24
- médiane = 2
Le score est globalement positif : les tâches sont en moyenne plutôt réalisées par les femmes.
Un score élevé signifie que davantage de tâches sont réalisées par les femmes. Un score négatif indiquerait l’inverse.
La distribution est assez dispersée (de -7 à +7), ce qui montre une diversité de situations.
Un score égal à 0 ne signifie pas forcément que tout est partagé :
- certaines tâches peuvent être féminines et d’autres masculines ;
- certaines peuvent être externalisées.
Le score simplifie une réalité plus complexe.
3.8.8 Limites du score
Un même score peut correspondre à des situations très différentes.
Par exemple, un score de 0 peut correspondre à :
- toutes les tâches sont partagées ;
- certaines tâches sont plutôt féminines et d’autres plutôt masculines ;
- certaines tâches sont réalisées par une autre personne.
3.8.9 Questions
- Que permet ce score ?
- Quelles informations sont perdues ?
- Pourquoi garder une analyse tâche par tâche ?
- Le score mesure t’il réellement l’égalité ?
- Quels autres méthodes auraient ont pu être utilisées ?
NoteVoir les réponses
Limites du score
Cet indicateur permet de résumer l’information et de comparer les individus.
Mais il fait perdre des informations :
- quelles tâches sont concernées ;
- les différences entre tâches ;
- les situations spécifiques (externalisation, etc.).
Il ne donne pas une mesure “objective” de l’égalité : il dépend des choix de codage (poids des tâches, catégories, etc.).
D’autres méthodes auraient été possibles :
- pondérer les tâches ;
- analyser séparément certains types de tâches ;
- utiliser des méthodes statistiques multivariées.
NotePoint clé
Un indicateur synthétique est utile pour résumer une information complexe.
Mais il repose toujours sur des choix :
- choix des variables incluses ;
- choix des catégories ;
- choix de la méthode de construction du score ;
- choix du traitement des cas ambigus.
Un score n’est pas seulement un calcul : c’est une construction.
3.9 8. Comparer les scores selon le groupe d’âge
La répartition des tâches varie t’elle selon le groupe d’âge (variable age_cat) ?
ERFI_couple_taches$age_cat <- cut(
ERFI_couple_taches$MA_AGEM_rec,
breaks = c(18, 30, 45, 60, 80),
include.lowest = TRUE,
right = FALSE,
labels = c("18-29 ans", "30-44 ans", "45-59 ans", "60 ans et plus")
)3.9.1 Comparer les scores moyens
TipVoir le code
#On calcule ici la moyenne du score selon le groupe d'âge.
tapply(
# Variable à analyser :
# → le score total de répartition des tâches
ERFI_couple_taches$score_total,
# Variable de groupe :
# → on sépare les individus selon le groupe d'âge
ERFI_couple_taches$age_cat,
# Fonction appliquée à chaque groupe :
# → ici, on calcule la moyenne
mean,
# Option : on ignore les valeurs manquantes
na.rm = TRUE
) 18-29 ans 30-44 ans 45-59 ans 60 ans et plus
1.500882 2.169860 2.504647 2.277469 3.9.2 Comparer les médianes
TipVoir le code
tapply(
ERFI_couple_taches$score_total,
ERFI_couple_taches$age_cat,
median,
na.rm = TRUE
) 18-29 ans 30-44 ans 45-59 ans 60 ans et plus
2 2 3 3 3.9.3 Visualiser les distributions
TipVoir le code
#On représente ici le score total selon le groupe d'âge à l’aide d’un boxplot.
boxplot(
# Formule : variable quantitative ~ variable de groupe
# → on compare le score selon les catégories d'âge
score_total ~ age_cat,
# Base de données utilisée
data = ERFI_couple_taches,
# Titre du graphique
main = "Score de répartition des tâches selon le groupe d'âge",
# Nom de l’axe horizontal (les groupes)
xlab = "Groupe d'âge",
# Nom de l’axe vertical (le score)
ylab = "Score total"
)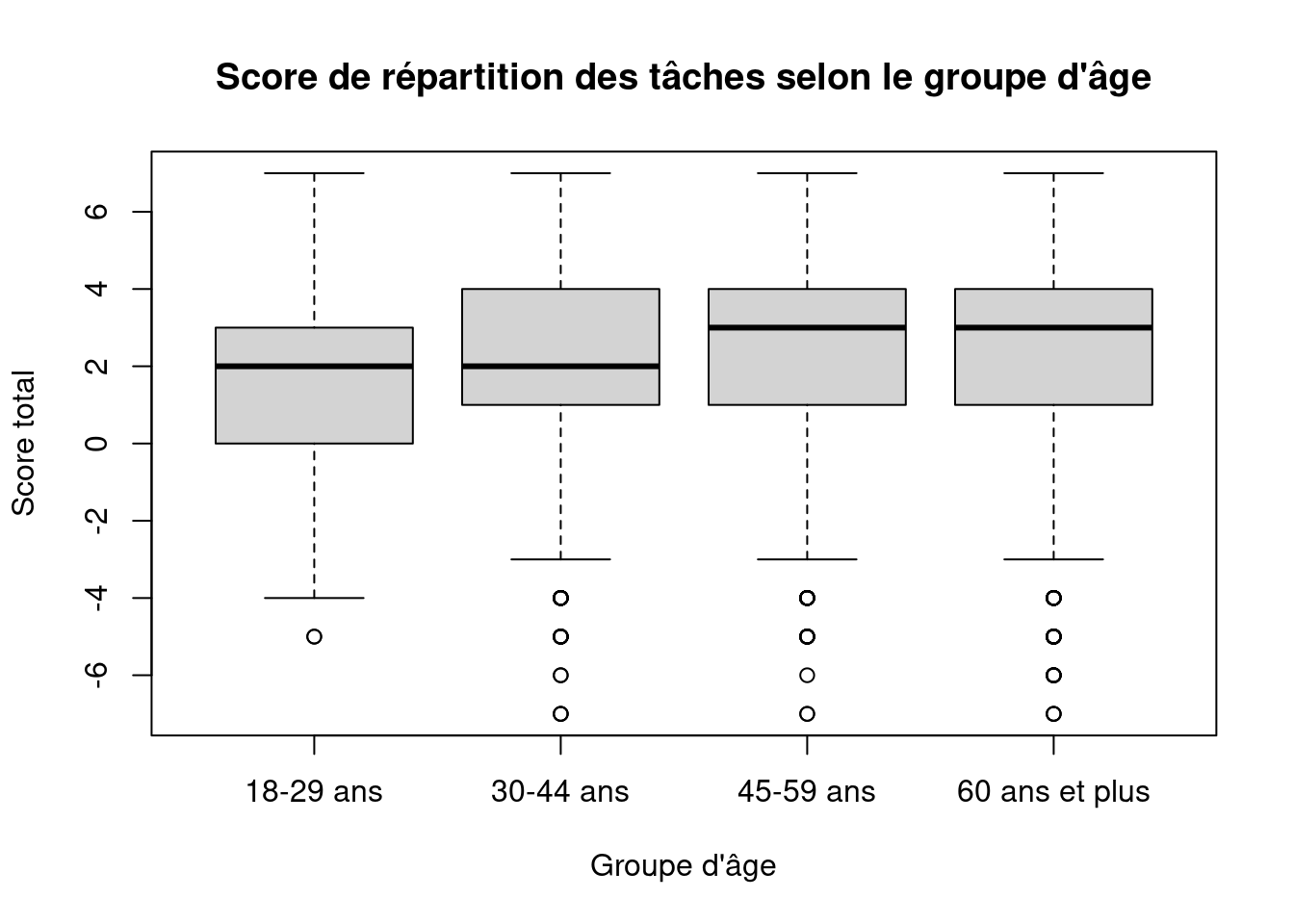
3.9.4 Questions
- Les scores diffèrent-ils selon l’âge ?
- Les distributions sont-elles proches ?
- Les groupes ont-ils des effectifs comparables ?
- Peut-on conclure à une causalité ?
NoteVoir les réponses
Les scores moyens varient selon le groupe d’âge :
- 18–29 ans : ≈ 1,50
- 30–44 ans : ≈ 2,17
- 45–59 ans : ≈ 2,50
- 60 ans et plus : ≈ 2,28
On observe une augmentation du score avec l’âge, jusqu’aux 45–59 ans, puis une légère baisse après 60 ans.
Comme un score plus élevé correspond à une répartition plus féminisée, cela suggère que :
- la répartition est un peu plus équilibrée chez les plus jeunes ;
- elle est plus féminisée chez les générations intermédiaires.
Les médianes confirment cette tendance :
- 18–29 ans et 30–44 ans : médiane = 2
- 45–59 ans et 60 ans et plus : médiane = 3
Les différences existent, mais restent modérées.
Le boxplot montre des distributions qui se chevauchent largement :
les écarts entre groupes sont donc réels mais pas très marqués.
Attention à l’interprétation :
- les groupes n’ont pas exactement les mêmes effectifs
(les 18–29 ans sont moins nombreux : ~10 %, contre ~30 % pour les autres groupes) ;
- d’autres variables peuvent intervenir (présence d’enfants, activité, génération, etc.).
On observe ici une association entre âge et répartition des tâches. Mais on ne peut pas conclure que l’âge cause ces différences.
L’âge peut être un indicateur de transformations sociales (générations, normes), mais il ne suffit pas à expliquer à lui seul la répartition des tâches.
WarningAttention
Comparer deux groupes permet d’observer une différence.
Mais cela ne suffit pas à établir une causalité.
Une différence observée peut dépendre :
- de la présence d’enfant(s) ;
- du niveau d’études ;
- de la situation professionnelle ;
- de la génération ;
- d’autres caractéristiques non observées.